# HIDDEN
# Clear previously defined variables
%reset -f
# Set directory for data loading to work properly
import os
os.chdir(os.path.expanduser('~/notebooks/18'))
# HIDDEN
import warnings
# Ignore numpy dtype warnings. These warnings are caused by an interaction
# between numpy and Cython and can be safely ignored.
# Reference: https://stackoverflow.com/a/40846742
warnings.filterwarnings("ignore", message="numpy.dtype size changed")
warnings.filterwarnings("ignore", message="numpy.ufunc size changed")
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
%matplotlib inline
import ipywidgets as widgets
from ipywidgets import interact, interactive, fixed, interact_manual
import nbinteract as nbi
sns.set()
sns.set_context('talk')
np.set_printoptions(threshold=20, precision=2, suppress=True)
pd.options.display.max_rows = 7
pd.options.display.max_columns = 8
pd.set_option('precision', 2)
# This option stops scientific notation for pandas
# pd.set_option('display.float_format', '{:.2f}'.format)
Hypothesis Testing and Confidence Intervals¶
In this section, we provide a brief review of hypothesis testing using the bootstrap and permutation tests. We assume familiarity with this topic since it is covered at length in Computational and Inferential Thinking, the textbook for Data 8. For a more thorough explanation of the concepts explained here, see Chapter 11, Chapter 12, and Chapter 13 of Computational and Inferential Thinking.
Hypothesis Tests¶
When applying data science techniques to different domains, we are often faced with questions about the world. For example, does drinking coffee cause sleep deprivation? Do autonomous vehicles crash more often then non-autonomous vehicles? Does drug X help treat pneumonia? To help answer these questions, we use hypothesis tests to make informed conclusions based on observed evidence/data.
Since data collection is often an imprecise process, we are often unsure whether the patterns in our dataset are due to noise or real phenomena. Hypothesis testing helps us determine whether a pattern could have happened because of random fluctuations in our data collection.
To explore hypothesis testing, we start with an example. The table baby contains information on baby weights at birth. It records the baby's birth weight in ounces and whether or not the mother smoked during pregnancy for 1174 babies.
# HIDDEN
baby = pd.read_csv('baby.csv')
baby = baby.loc[:, ["Birth Weight", "Maternal Smoker"]]
baby
Design¶
We would like to see whether maternal smoking was associated with birth weight. To set up our hypothesis test, we can represent the two views of the world using the following null and alternative hypotheses:
Null hypothesis: In the population, the distribution of birth weights of babies is the same for mothers who don't smoke as for mothers who do. The difference in the sample is due to chance.
Alternative hypothesis: In the population, the babies of the mothers who smoke have a lower birth weight, on average, than the babies of the non-smokers.
Our ultimate goal is to make a decision between these two data generation models. One important point to notice is that we construct our hypotheses about the parameters of the data generation model rather than the outcome of the experiment. For example, we should not construct a null hypothesis such as "The birth weights of smoking mothers will be equal to the birth weights of nonsmoking mothers", since there is natural variability in the outcome of this process.
The null hypothesis emphasizes that if the data look different from what the null hypothesis predicts, the difference is due to nothing but chance. Informally, the alternative hypothesis says that the observed difference is "real."
We should take a closer look at the structure of our alternative hypothesis. In our current set up, notice that we would reject the null hypothesis if the birth weights of babies of the mothers who smoke are significantly lower than the birth weights of the babies of the mothers who do not smoke. In other words, the alternative hypothesis encompasses/supports one side of the distribution. We call this a one-sided alternative hypothesis. In general, we would only want to use this type of alternative hypothesis if we have a good reason to believe that it is impossible to see babies of the mothers who smoke have a higher birth weight, on average.
To visualize the data, we've plotted histograms of the baby weights for babies born to maternal smokers and non-smokers.
# HIDDEN
plt.figure(figsize=(9, 6))
smokers_hist = (baby.loc[baby["Maternal Smoker"], "Birth Weight"]
.hist(normed=True, alpha=0.8, label="Maternal Smoker"))
non_smokers_hist = (baby.loc[~baby["Maternal Smoker"], "Birth Weight"]
.hist(normed=True, alpha=0.8, label="Not Maternal Smoker"))
smokers_hist.set_xlabel("Baby Birth Weights")
smokers_hist.set_ylabel("Proportion per Unit")
smokers_hist.set_title("Distribution of Birth Weights")
plt.legend()
plt.show()
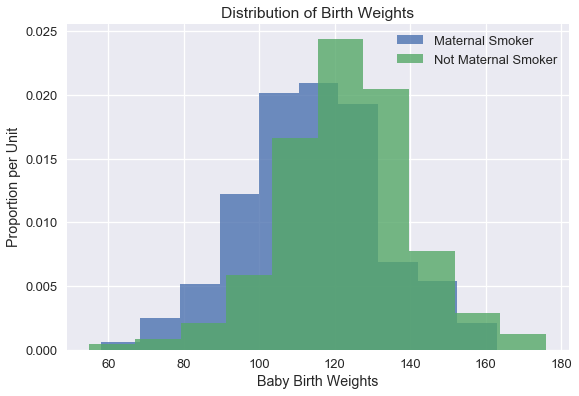
The weights of the babies of the mothers who smoked seem lower on average than the weights of the babies of the non-smokers. Could this difference likely have occurred due to random variation? We can try to answer this question using a hypothesis test.
To perform a hypothesis test, we assume a particular model for generating the data; then, we ask ourselves, what is the chance we would see an outcome as extreme as the one that we observed? Intuitively, if the chance of seeing the outcome we observed is very small, the model that we assumed may not be the appropriate model.
In particular, we assume that the null hypothesis and its probability model, the null model, is true. In other words, we assume that the null hypothesis is true and focus on what the value of the statistic would be under under the null hypothesis. This chance model says that there is no underlying difference; the distributions in the samples are different just due to chance.
Test Statistic¶
In our example, we would assume that maternal smoking has no effect on baby weight (where any observed difference is due to chance). In order to choose between our hypotheses, we will use the difference between the two group means as our test statistic. Formally, our test statistic is
$$\mu_{\text{smoking}} - \mu_{\text{non-smoking}}$$
so that small values (that is, large negative values) of this statistic will favor the alternative hypothesis. Let's calculate the observed value of test statistic:
nonsmoker = baby.loc[~baby["Maternal Smoker"], "Birth Weight"]
smoker = baby.loc[baby["Maternal Smoker"], "Birth Weight"]
observed_difference = np.mean(smoker) - np.mean(nonsmoker)
observed_difference
If there were really no difference between the two distributions in the underlying population, then whether each mother was a maternal smoker or not should not affect the average birth weight. In other words, the label True or False with respect to maternal smoking should make no difference to the average.
Therefore, in order to simulate the test statistic under the null hypothesis, we can shuffle all the birth weights randomly among the mothers. We conduct this random permutation below.
def shuffle(series):
'''
Shuffles a series and resets index to preserve shuffle when adding series
back to DataFrame.
'''
return series.sample(frac=1, replace=False).reset_index(drop=True)
baby["Shuffled"] = shuffle(baby["Birth Weight"])
baby
Conducting a Permutation Test¶
Tests based on random permutations of the data are called permutation tests. In the cell below, we will simulate our test statistic many times and collect the differences in an array.
differences = np.array([])
repetitions = 5000
for i in np.arange(repetitions):
baby["Shuffled"] = shuffle(baby["Birth Weight"])
# Find the difference between the means of two randomly assigned groups
nonsmoker = baby.loc[~baby["Maternal Smoker"], "Shuffled"]
smoker = baby.loc[baby["Maternal Smoker"], "Shuffled"]
simulated_difference = np.mean(smoker) - np.mean(nonsmoker)
differences = np.append(differences, simulated_difference)
We plot a histogram of the simulated difference in means below:
# HIDDEN
differences_df = pd.DataFrame()
differences_df["differences"] = differences
diff_hist = differences_df.loc[:, "differences"].hist(normed = True)
diff_hist.set_xlabel("Birth Weight Difference")
diff_hist.set_ylabel("Proportion per Unit")
diff_hist.set_title("Distribution of Birth Weight Differences");
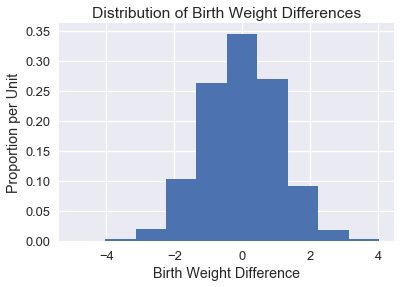
It makes intuitive sense that the distribution of differences is centered around 0 since the two groups should have the same average under the null hypothesis.
In order to draw a conclusion for this hypothesis test, we should calculate the p-value. The empirical p-value of the test is the proportion of simulated differences that were equal to or less than the observed difference.
p_value = np.count_nonzero(differences <= observed_difference) / repetitions
p_value
At the beginning of the hypothesis test we typically choose a p-value threshold of significance (commonly denoted as alpha). If our p-value is below our significance threshold, then we reject the null hypothesis. The most commonly chosen thresholds are 0.01 and 0.05, where 0.01 is considered to be more "strict" since we would need more evidence in favor of the alternative hypothesis to reject the null hypothesis.
In either of these two cases, we reject the null hypothesis since the p-value is less than the significance threshold.
Bootstrap Confidence Intervals¶
Data scientists must often estimate an unknown population parameter using a random sample. Although we would ideally like to take numerous samples from the population to generate a sampling distribution, we are often limited to a single sample by money and time.
Fortunately, a large, randomly collected sample looks like the original population. The bootstrap procedure uses this fact to simulate new samples by resampling from the original sample.
To conduct the bootstrap, we perform the following steps:
- Sample with replacement from the original sample (now the bootstrap population). These samples are called bootstrap samples. We typically take thousands of bootstrap samples (~10,000 is common).
- Calculate the statistic of interest for each bootstrap sample. This statistic is called the bootstrap statistic, and the empirical distribution of these bootstrap statistics is an approximation to the sampling distribution of the bootstrapped statistic.

We may use the bootstrap sampling distribution to create a confidence interval which we use to estimate the value of the population parameter.
Since the birth weight data provides a large, random sample, we may act as if the data on mothers who did not smoke are representative of the population of nonsmoking mothers. Similarly, we act as if the data for smoking mothers are representative of the population of smoking mothers.
Therefore, we treat our original sample as the bootstrap population to perform the bootstrap procedure:
- Draw a sample with replacement from the nonsmoking mothers and calculate the mean birth weight for these mothers. We also draw a sample with replacement from the smoking mothers and calculate the mean birth weight.
- Calculate the difference in means.
- Repeat the above process 10000 times, obtaining 10000 mean differences.
This procedure gives us a empirical sampling distribution of differences in mean baby weights.
def resample(sample):
return np.random.choice(sample, size=len(sample))
def bootstrap(sample, stat, replicates):
return np.array([
stat(resample(sample)) for _ in range(replicates)
])
nonsmoker = baby.loc[~baby["Maternal Smoker"], "Birth Weight"]
smoker = baby.loc[baby["Maternal Smoker"], "Birth Weight"]
nonsmoker_means = bootstrap(nonsmoker, np.mean, 10000)
smoker_means = bootstrap(smoker, np.mean, 10000)
mean_differences = smoker_means - nonsmoker_means
We plot the empirical distribution of the difference in means below:
# HIDDEN
mean_differences_df = pd.DataFrame()
mean_differences_df["differences"] = np.array(mean_differences)
mean_diff = mean_differences_df.loc[:, "differences"].hist(normed=True)
mean_diff.set_xlabel("Birth Weight Difference")
mean_diff.set_ylabel("Proportion per Unit")
mean_diff.set_title("Distribution of Birth Weight Differences");
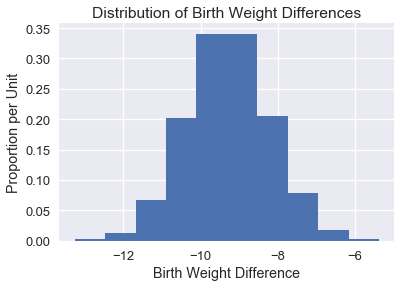
Finally, to construct a 95% confidence interval we take the 2.5th and 97.5th percentiles of the bootstrap statistics:
(np.percentile(mean_differences, 2.5),
np.percentile(mean_differences, 97.5))
This confidence interval allows us to state with 95% confidence that the population mean difference in birth weights is between -11.37 and -7.18 ounces.
Summary¶
In this section, we review hypothesis testing using the permutation test and confidence intervals using the bootstrap. To conduct a hypothesis test, we must state our null and alternative hypotheses, select an appropriate test statistic, and perform the testing procedure to calculate a p-value. To create a confidence interval, we select an appropriate test statistic, bootstrap the original sample to generate an empirical distribution of the test statistic, and select the quantiles corresponding to our desired confidence level.