# HIDDEN
# Clear previously defined variables
%reset -f
# Set directory for data loading to work properly
import os
os.chdir(os.path.expanduser('~/notebooks/13'))
# HIDDEN
import warnings
# Ignore numpy dtype warnings. These warnings are caused by an interaction
# between numpy and Cython and can be safely ignored.
# Reference: https://stackoverflow.com/a/40846742
warnings.filterwarnings("ignore", message="numpy.dtype size changed")
warnings.filterwarnings("ignore", message="numpy.ufunc size changed")
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
%matplotlib inline
import ipywidgets as widgets
from ipywidgets import interact, interactive, fixed, interact_manual
import nbinteract as nbi
sns.set()
sns.set_context('talk')
np.set_printoptions(threshold=20, precision=2, suppress=True)
pd.options.display.max_rows = 7
pd.options.display.max_columns = 8
pd.set_option('precision', 2)
# This option stops scientific notation for pandas
# pd.set_option('display.float_format', '{:.2f}'.format)
# HIDDEN
from scipy.optimize import minimize as sci_min
def minimize(cost_fn, grad_cost_fn, X, y, progress=True):
'''
Uses scipy.minimize to minimize cost_fn using a form of gradient descent.
'''
theta = np.zeros(X.shape[1])
iters = 0
def objective(theta):
return cost_fn(theta, X, y)
def gradient(theta):
return grad_cost_fn(theta, X, y)
def print_theta(theta):
nonlocal iters
if progress and iters % progress == 0:
print(f'theta: {theta} | cost: {cost_fn(theta, X, y):.2f}')
iters += 1
print_theta(theta)
return sci_min(
objective, theta, method='BFGS', jac=gradient, callback=print_theta,
tol=1e-7
).x
Linear Regression Case Study¶
In this section, we perform an end-to-end case study of applying the linear regression model to a dataset. The dataset we will be working with has various attributes, such as length and girth, of donkeys.
Our task is to predict a donkey's weight using linear regression.
Preliminary Data Overview¶
We will begin by reading in the dataset and taking a quick peek at its contents.
donkeys = pd.read_csv("donkeys.csv")
donkeys.head()
It's always a good idea to look at how much data we have by looking at the dimensions of the dataset. If we have a large number of observations, printing out the entire dataframe may crash our notebook.
donkeys.shape
The dataset is relatively small, with only 544 rows of observations and 8 columns. Let's look at what columns are available to us.
donkeys.columns.values
A good understanding of our data can guide our analysis, so we should understand what each of these columns represent. A few of these columns are self-explanatory, but others require a little more explanation:
BCS: Body Condition Score (a physical health rating)Girth: the measurement around the middle of the donkeyWeightAlt: the second weighing (31 donkeys in our data were weighed twice in order to check the accuracy of the scale)
It is also a good idea to determine which variables are quantitative and which are categorical.
Quantitative: Length, Girth, Height, Weight, WeightAlt
Categorical: BCS, Age, Sex
Data Cleaning¶
In this section, we will check the data for any abnormalities that we have to deal with.
By examining WeightAlt more closely, we can make sure that the scale is accurate by taking the difference between the two different weighings and plotting them.
difference = donkeys['WeightAlt'] - donkeys['Weight']
sns.distplot(difference.dropna());
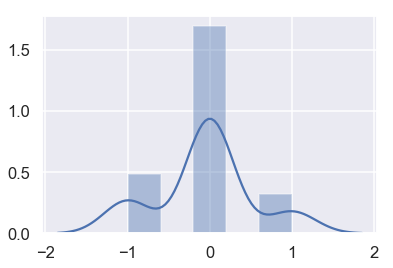
The measurements are all within 1 kg of each other, which seems reasonable.
Next, we can look for unusual values that might indicate errors or other problems. We can use the quantile function in order to detect anomalous values.
donkeys.quantile([0.005, 0.995])
For each of these numerical columns, we can look at which rows fall outside of these quantiles and what values they take on. Consider that we want our model to apply to only healthy and mature donkeys.
First, let's look at the BCS column.
donkeys[(donkeys['BCS'] < 1.5) | (donkeys['BCS'] > 4)]['BCS']
Also looking at the barplot of BCS:
plt.hist(donkeys['BCS'], density=True)
plt.xlabel('BCS');
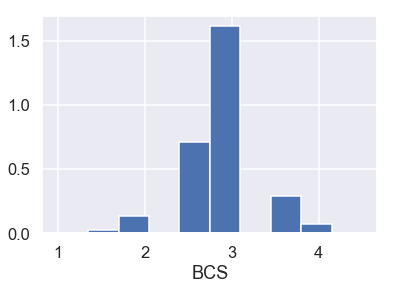
Considering that BCS is an indication of the health of a donkey, a BCS of 1 represents an extremely emaciated donkey and a BCS of 4.5 an overweight donkey. Also looking at the barplot, there only appear to be two donkeys with such outlying BCS values. Thus, we remove these two donkeys.
Now, let's look at Length, Girth, and Height.
donkeys[(donkeys['Length'] < 71.145) | (donkeys['Length'] > 111)]['Length']
donkeys[(donkeys['Girth'] < 90) | (donkeys['Girth'] > 131.285)]['Girth']
donkeys[(donkeys['Height'] < 89) | (donkeys['Height'] > 112)]['Height']
For these three columns, the donkey in row 8 seems to have a much smaller value than the cut-off while the other anomalous donkeys are close to the cut-off and likely do not need to be removed.
Finally, let's take a look at Weight.
donkeys[(donkeys['Weight'] < 71.715) | (donkeys['Weight'] > 214)]['Weight']
The first 2 and last 2 donkeys in the list are far off from the cut-off and most likely should be removed. The middle donkey can be included.
Since WeightAlt closely corresponds to Weight, we skip checking this column for anomalies. Summarizing what we have learned, here is how we want to filter our donkeys:
- Keep donkeys with
BCSin the range 1.5 and 4 - Keep donkeys with
Weightbetween 71 and 214
donkeys_c = donkeys[(donkeys['BCS'] >= 1.5) & (donkeys['BCS'] <= 4) &
(donkeys['Weight'] >= 71) & (donkeys['Weight'] <= 214)]
Train-Test Split¶
Before we proceed with our data analysis, we divide our data into an 80/20 split, using 80% of our data to train our model and setting aside the other 20% for evaluation of the model.
X_train, X_test, y_train, y_test = train_test_split(donkeys_c.drop(['Weight'], axis=1),
donkeys_c['Weight'],
test_size=0.2,
random_state=42)
X_train.shape, X_test.shape
Let's also create a function that evaluates our predictions on the test set. Let's use mean squared error.
def mse_test_set(predictions):
return float(np.sum((predictions - y_test) ** 2))
Exploratory Data Analysis and Visualization¶
As usual, we will explore our data before attempting to fit a model to it.
First, we will examine the categorical variables with boxplots.
# HIDDEN
sns.boxplot(x=X_train['BCS'], y=y_train);
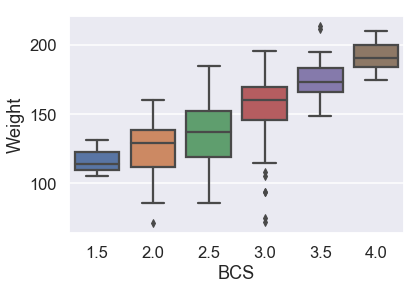
It seems like median weight increases with BCS, but not linearly.
# HIDDEN
sns.boxplot(x=X_train['Sex'], y=y_train,
order = ['female', 'stallion', 'gelding']);
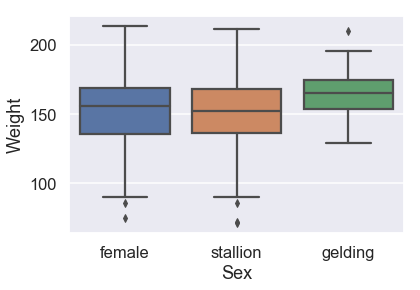
It seems like the sex of the donkey doesn't appear to cause much of a difference in weight.
# HIDDEN
sns.boxplot(x=X_train['Age'], y=y_train,
order = ['<2', '2-5', '5-10', '10-15', '15-20', '>20']);
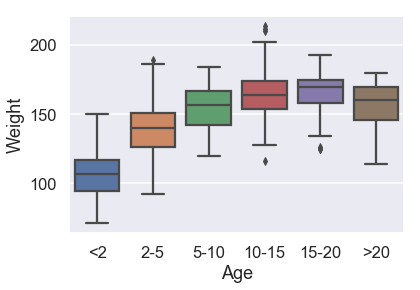
For donkeys over 5, the weight distribution is not too different.
Now, let's look at the quantitative variables. We can plot each of them against the target variable.
# HIDDEN
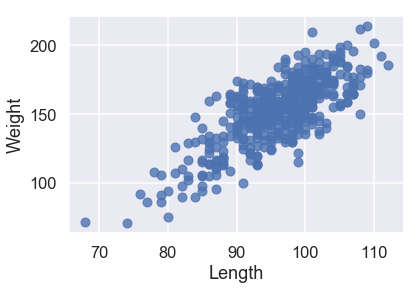
X_train['Weight'] = y_train
sns.regplot('Length', 'Weight', X_train, fit_reg=False);
# HIDDEN
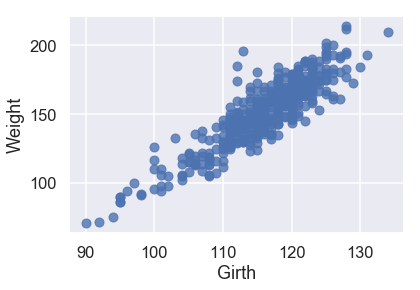
sns.regplot('Girth', 'Weight', X_train, fit_reg=False);
# HIDDEN
sns.regplot('Height', 'Weight', X_train, fit_reg=False);
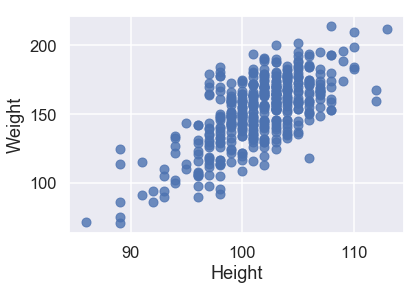
All three of our quantitative features have a linear relationship with our target variable of Weight, so we will not have to perform any transformations on our input data.
It is also a good idea to see if our features are linear with each other. We plot two below:
# HIDDEN
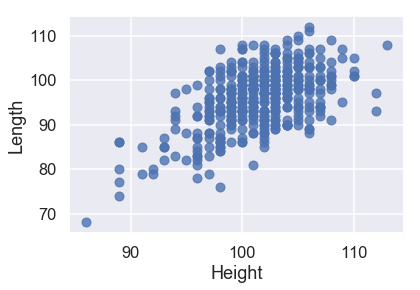
sns.regplot('Height', 'Length', X_train, fit_reg=False);
# HIDDEN
sns.regplot('Height', 'Girth', X_train, fit_reg=False);
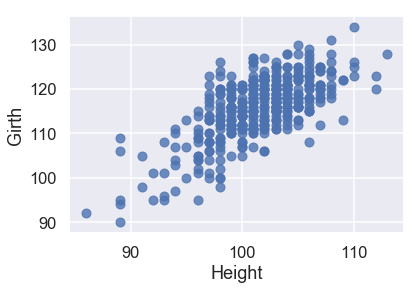
From these plots, we can see that our predictor variables also have strong linear relationships with each other. This makes our model harder to interpret, so we should keep this in mind after we create our model.
Simpler Linear Models¶
Rather than using all of our data at once, let's try to fit linear models to one or two variables first.
Below are three simple linear regression models using just one quantitative variable. Which model appears to be the best?
# HIDDEN
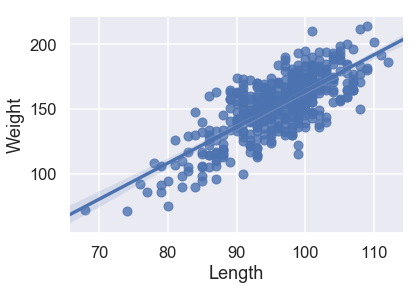
sns.regplot('Length', 'Weight', X_train, fit_reg=True);
# HIDDEN
model = LinearRegression()
model.fit(X_train[['Length']], X_train['Weight'])
predictions = model.predict(X_test[['Length']])
print("MSE:", mse_test_set(predictions))
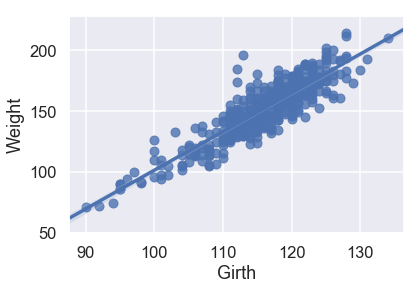
sns.regplot('Girth', 'Weight', X_train, fit_reg=True);
# HIDDEN
model = LinearRegression()
model.fit(X_train[['Girth']], X_train['Weight'])
predictions = model.predict(X_test[['Girth']])
print("MSE:", mse_test_set(predictions))
sns.regplot('Height', 'Weight', X_train, fit_reg=True);
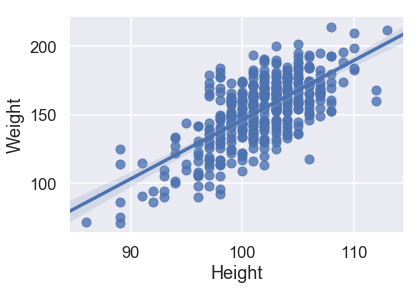
# HIDDEN
model = LinearRegression()
model.fit(X_train[['Height']], X_train['Weight'])
predictions = model.predict(X_test[['Height']])
print("MSE:", mse_test_set(predictions))
Looking at the scatterplots and the mean squared errors, it seems like Girth is the best sole predictor of Weight as it has the strongest linear relationship with Weight and the smallest mean squared error.
Can we do better with two variables? Let's try fitting a linear model using both Girth and Length. Although it is not as easy to visualize this model, we can still look at the MSE of this model.
# HIDDEN
model = LinearRegression()
model.fit(X_train[['Girth', 'Length']], X_train['Weight'])
predictions = model.predict(X_test[['Girth', 'Length']])
print("MSE:", mse_test_set(predictions))
Wow! Looks like our MSE went down from around 13000 with just Girth alone to 10000 with Girth and Length. Using including the second variable improved our model.
We can also use categorical variables in our model. Let's now look at a linear model using the categorical variable of Age. This is the plot of Age versus Weight:
# HIDDEN
sns.stripplot(x='Age', y='Weight', data=X_train, order=['<2', '2-5', '5-10', '10-15', '15-20', '>20']);
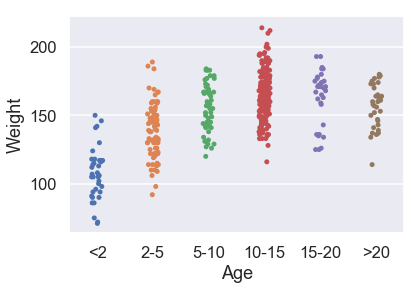
Seeing how Age is a categorical variable, we need to introduce dummy variables in order to produce a linear regression model.
# HIDDEN
just_age_and_weight = X_train[['Age', 'Weight']]
with_age_dummies = pd.get_dummies(just_age_and_weight, columns=['Age'])
model = LinearRegression()
model.fit(with_age_dummies.drop('Weight', axis=1), with_age_dummies['Weight'])
just_age_and_weight_test = X_test[['Age']]
with_age_dummies_test = pd.get_dummies(just_age_and_weight_test, columns=['Age'])
predictions = model.predict(with_age_dummies_test)
print("MSE:", mse_test_set(predictions))
A MSE of around 40000 is worse than what we could get using any single one of the quantitative variables, but this variable could still prove to be useful in our linear model.
Let's try to interpret this linear model. Note that every donkey that falls into an age category, say 2-5 years of age, will receive the same prediction because they share the input values: a 1 in the column corresponding to 2-5 years of age, and 0 in all other columns. Thus, we can interpret categorical variables as simply changing the constant in the model because the categorical variable separates the donkeys into groups and gives one prediction for all donkeys within that group.
Our next step is to create a final model using both our categorical variables and multiple quantitative variables.
Transforming Variables¶
Recall from our boxplots that Sex was not a useful variable, so we will drop it. We will also remove the WeightAlt column because we only have its value for 31 donkeys. Finally, using get_dummies, we transform the categorical variables BCS and Age into dummy variables so that we can include them in the model.
# HIDDEN
X_train.drop('Weight', axis=1, inplace=True)
# HIDDEN
pd.set_option('max_columns', 15)
X_train.drop(['Sex', 'WeightAlt'], axis=1, inplace=True)
X_train = pd.get_dummies(X_train, columns=['BCS', 'Age'])
X_train.head()
Recall that we noticed that the weight distribution of donkeys over the age of 5 is not very different. Thus, let's combine the columns Age_10-15, Age_15-20, and Age_>20 into one column.
age_over_10 = X_train['Age_10-15'] | X_train['Age_15-20'] | X_train['Age_>20']
X_train['Age_>10'] = age_over_10
X_train.drop(['Age_10-15', 'Age_15-20', 'Age_>20'], axis=1, inplace=True)
Since we do not want our matrix to be over-parameterized, we should drop one category from the BCS and Age dummies.
X_train.drop(['BCS_3.0', 'Age_5-10'], axis=1, inplace=True)
X_train.head()
We should also add a column of biases in order to have a constant term in our model.
X_train = X_train.assign(bias=1)
# HIDDEN
X_train = X_train.reindex(columns=['bias'] + list(X_train.columns[:-1]))
X_train.head()
Multiple Linear Regression Model¶
We are finally ready to fit our model to all of the variables we have deemed important and transformed into the proper form.
Our model looks like this:
$$ f_\theta (\textbf{x}) = \theta_0 + \theta_1 (Length) + \theta_2 (Girth) + \theta_3 (Height) + ... + \theta_{11} (Age_>10) $$
Here are the functions we defined in the multiple linear regression lesson, which we will use again:
def linear_model(thetas, X):
'''Returns predictions by a linear model on x_vals.'''
return X @ thetas
def mse_cost(thetas, X, y):
return np.mean((y - linear_model(thetas, X)) ** 2)
def grad_mse_cost(thetas, X, y):
n = len(X)
return -2 / n * (X.T @ y - X.T @ X @ thetas)
In order to use the above functions, we need X, and y. These can both be obtained from our data frames. Remember that X and y have to be numpy matrices in order to be able to multiply them with @ notation.
X_train = X_train.values
y_train = y_train.values
Now we just need to call the minimize function defined in a previous section.
thetas = minimize(mse_cost, grad_mse_cost, X_train, y_train)
Our linear model is:
$y = -204.03 + 0.93x_1 + ... -7.22x_{9} + 1.95x_{11}$
Let's compare this equation that we obtained to the one we would get if we had used sklearn's LinearRegression model instead.
model = LinearRegression(fit_intercept=False) # We already accounted for it with the bias column
model.fit(X_train[:, :14], y_train)
print("Coefficients", model.coef_)
The coefficients look exactly the same! Our homemade functions create the same model as an established Python package!
We successfully fit a linear model to our donkey data! Nice!
Evaluating our Model¶
Our next step is to evaluate our model's performance on the test set. We need to perform the same data pre-processing steps on the test set as we did on the training set before we can pass it into our model.
X_test.drop(['Sex', 'WeightAlt'], axis=1, inplace=True)
X_test = pd.get_dummies(X_test, columns=['BCS', 'Age'])
age_over_10 = X_test['Age_10-15'] | X_test['Age_15-20'] | X_test['Age_>20']
X_test['Age_>10'] = age_over_10
X_test.drop(['Age_10-15', 'Age_15-20', 'Age_>20'], axis=1, inplace=True)
X_test.drop(['BCS_3.0', 'Age_5-10'], axis=1, inplace=True)
X_test = X_test.assign(bias=1)
# HIDDEN
X_test = X_test.reindex(columns=['bias'] + list(X_test.columns[:-1]))
X_test
We pass X_test into predict of our LinearRegression model:
X_test = X_test.values
predictions = model.predict(X_test)
Let's look at the mean squared error:
mse_test_set(predictions)
With these predictions, we can also make a residual plot:
# HIDDEN
y_test = y_test.values
resid = y_test - predictions
resid_prop = resid / y_test
plt.scatter(np.arange(len(resid_prop)), resid_prop, s=15)
plt.axhline(0)
plt.title('Residual proportions (resid / actual Weight)')
plt.xlabel('Index of row in data')
plt.ylabel('Error proportion');
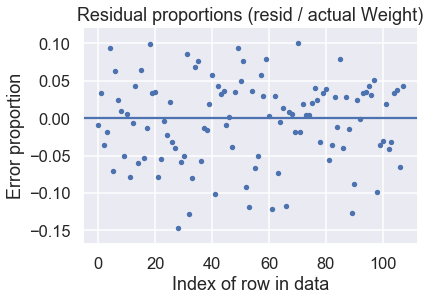
Looks like our model does pretty well! The residual proportions indicate that our predictions are mostly within 15% of the correct value.