# HIDDEN
# Clear previously defined variables
%reset -f
# Set directory for data loading to work properly
import os
os.chdir(os.path.expanduser('~/notebooks/06'))
# HIDDEN
import warnings
# Ignore numpy dtype warnings. These warnings are caused by an interaction
# between numpy and Cython and can be safely ignored.
# Reference: https://stackoverflow.com/a/40846742
warnings.filterwarnings("ignore", message="numpy.dtype size changed")
warnings.filterwarnings("ignore", message="numpy.ufunc size changed")
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
%matplotlib inline
import ipywidgets as widgets
from ipywidgets import interact, interactive, fixed, interact_manual
import nbinteract as nbi
sns.set()
sns.set_context('talk')
np.set_printoptions(threshold=20, precision=2, suppress=True)
pd.options.display.max_rows = 7
pd.options.display.max_columns = 8
pd.set_option('precision', 2)
# This option stops scientific notation for pandas
# pd.set_option('display.float_format', '{:.2f}'.format)
# HIDDEN
def df_interact(df):
'''
Outputs sliders that show rows and columns of df
'''
def peek(row=0, col=0):
return df.iloc[row:row + 5, col:col + 8]
interact(peek, row=(0, len(df), 5), col=(0, len(df.columns) - 6))
print('({} rows, {} columns) total'.format(df.shape[0], df.shape[1]))
Visualizing Quantitative Data¶
We generally use different types of charts to visualize quantitative (numerical) data and qualitative (ordinal or nominal) data.
For quantitative data, we most often use histograms, box plots, and scatter plots.
We can use the seaborn plotting library to create these plots in Python. We will use a dataset containing information about passengers aboard the Titanic.
# Import seaborn and apply its plotting styles
import seaborn as sns
sns.set()
# Load the dataset and drop N/A values to make plot function calls simpler
ti = sns.load_dataset('titanic').dropna().reset_index(drop=True)
# This table is too large to fit onto a page so we'll output sliders to
# pan through different sections.
df_interact(ti)
Histograms¶
We can see that the dataset contains one row for every passenger. Each row includes the age of the passenger and the amount the passenger paid for a ticket. Let's visualize the ages using a histogram. We can use seaborn's distplot function:
# Adding a semi-colon at the end tells Jupyter not to output the
# usual <matplotlib.axes._subplots.AxesSubplot> line
sns.distplot(ti['age']);
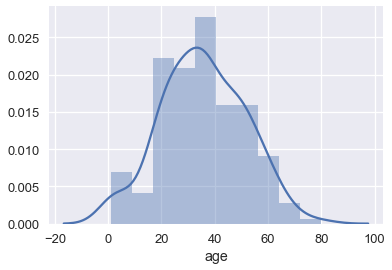
By default, seaborn's distplot function will output a smoothed curve that roughly fits the distribution. We can also add a rugplot which marks each individual point on the x-axis:
sns.distplot(ti['age'], rug=True);
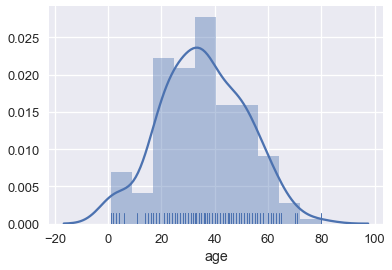
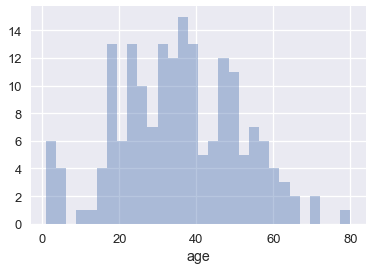
We can also plot the distribution itself. Adjusting the number of bins shows that there were a number of children on board.
sns.distplot(ti['age'], kde=False, bins=30);
Box plots¶
Box plots are a convenient way to see where most of the data lie. Typically, we use the 25th and 75th percentiles of the data as the start and endpoints of the box and draw a line within the box for the 50th percentile (the median). We draw two "whiskers" that extend to show the the remaining data except outliers, which are marked as individual points outside the whiskers.
sns.boxplot(x='fare', data=ti);
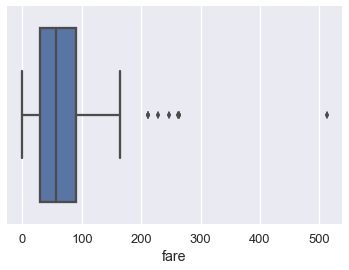
We typically use the Inter-Quartile Range (IQR) to determine which points are considered outliers for the box plot. The IQR is the difference between the 75th percentile of the data and the 25th percentile.
lower, upper = np.percentile(ti['fare'], [25, 75])
iqr = upper - lower
iqr
Values greater than 1.5 $\times$ IQR above the 75th percentile and less than 1.5 $\times$ IQR below the 25th percentile are considered outliers and we can see them marked indivdiually on the boxplot above:
upper_cutoff = upper + 1.5 * iqr
lower_cutoff = lower - 1.5 * iqr
upper_cutoff, lower_cutoff
Although histograms show the entire distribution at once, box plots are often easier to understand when we split the data by different categories. For example, we can make one box plot for each passenger type:
sns.boxplot(x='fare', y='who', data=ti);
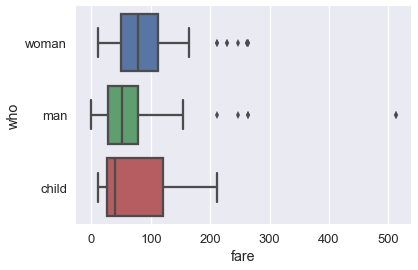
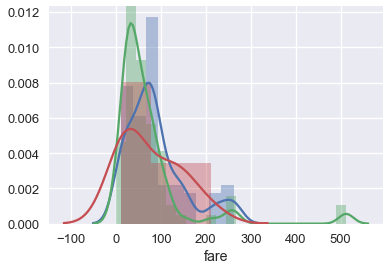
The separate box plots are much easier to understand than the overlaid histogram below which plots the same data:
sns.distplot(ti.loc[ti['who'] == 'woman', 'fare'])
sns.distplot(ti.loc[ti['who'] == 'man', 'fare'])
sns.distplot(ti.loc[ti['who'] == 'child', 'fare']);
Brief Aside on Using Seaborn¶
You may have noticed that the boxplot call to make separate box plots for the who column was simpler than the equivalent code to make an overlaid histogram. Although sns.distplot takes in an array or Series of data, most other seaborn functions allow you to pass in a DataFrame and specify which column to plot on the x and y axes. For example:
# Plots the `fare` column of the `ti` DF on the x-axis
sns.boxplot(x='fare', data=ti);
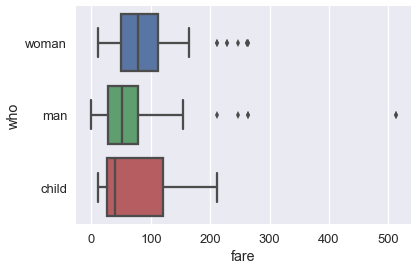
When the column is categorical (the 'who' column contained 'woman', 'man', and 'child'), seaborn will automatically split the data by category before plotting. This means we don't have to filter out each category ourselves like we did for sns.distplot.
# fare (numerical) on the x-axis,
# who (nominal) on the y-axis
sns.boxplot(x='fare', y='who', data=ti);
Scatter Plots¶
Scatter plots are used to compare two quantitative variables. We can compare the age and fare columns of our Titanic dataset using a scatter plot.
sns.lmplot(x='age', y='fare', data=ti);
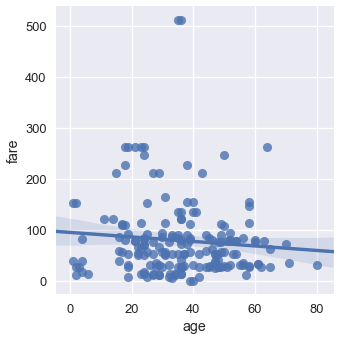
By default seaborn will also fit a regression line to our scatterplot and bootstrap the scatterplot to create a 95% confidence interval around the regression line shown as the light blue shading around the line above. In this case, the regression line doesn't seem to fit the scatter plot very well so we can turn off the regression.
sns.lmplot(x='age', y='fare', data=ti, fit_reg=False);
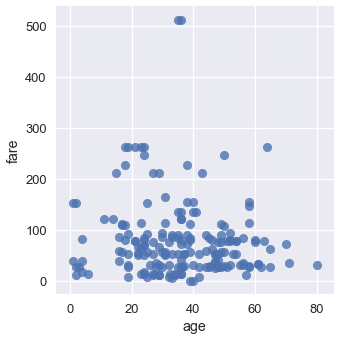
We can color the points using a categorical variable. Let's use the who column once more:
sns.lmplot(x='age', y='fare', hue='who', data=ti, fit_reg=False);
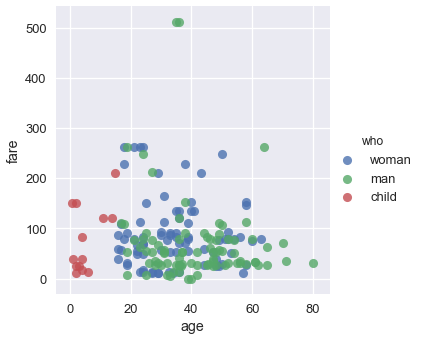
From this plot we can see that all passengers below the age of 18 or so were marked as child. There doesn't seem to be a noticable split between male and female passenger fares, although the two most expensive tickets were purchased by males.