# HIDDEN
# Clear previously defined variables
%reset -f
# Set directory for data loading to work properly
import os
os.chdir(os.path.expanduser('~/notebooks/14'))
# HIDDEN
import warnings
# Ignore numpy dtype warnings. These warnings are caused by an interaction
# between numpy and Cython and can be safely ignored.
# Reference: https://stackoverflow.com/a/40846742
warnings.filterwarnings("ignore", message="numpy.dtype size changed")
warnings.filterwarnings("ignore", message="numpy.ufunc size changed")
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
%matplotlib inline
import ipywidgets as widgets
from ipywidgets import interact, interactive, fixed, interact_manual
import nbinteract as nbi
sns.set()
sns.set_context('talk')
np.set_printoptions(threshold=20, precision=2, suppress=True)
pd.options.display.max_rows = 7
pd.options.display.max_columns = 8
pd.set_option('precision', 2)
# This option stops scientific notation for pandas
# pd.set_option('display.float_format', '{:.2f}'.format)
# HIDDEN
def df_interact(df, nrows=7, ncols=7):
'''
Outputs sliders that show rows and columns of df
'''
def peek(row=0, col=0):
return df.iloc[row:row + nrows, col:col + ncols]
if len(df.columns) <= ncols:
interact(peek, row=(0, len(df) - nrows, nrows), col=fixed(0))
else:
interact(peek,
row=(0, len(df) - nrows, nrows),
col=(0, len(df.columns) - ncols))
print('({} rows, {} columns) total'.format(df.shape[0], df.shape[1]))
# HIDDEN
# To determine which columns to regress
# ice_orig = pd.read_csv('icecream_orig.csv')
# cols = ['aerated', 'afterfeel', 'almond', 'buttery', 'color', 'cooling',
# 'creamy', 'doughy', 'eggy', 'fat', 'fat_level', 'fatty', 'hardness',
# 'ice_crystals', 'id', 'liking_flavor', 'liking_texture', 'melt_rate',
# 'melting_rate', 'milky', 'sugar', 'sugar_level', 'sweetness',
# 'tackiness', 'vanilla']
# melted = ice_orig.melt(id_vars='overall', value_vars=cols, var_name='type')
# sns.lmplot(x='value', y='overall', col='type', col_wrap=5, data=melted,
# sharex=False, fit_reg=False)
Predicting Ice Cream Ratings¶
Suppose we are trying to create new, popular ice cream flavors. We are interested in the following regression problem: given the sweetness of an ice cream flavor, predict its overall taste rating out of 7.
ice = pd.read_csv('icecream.csv')
ice
Although we expect that an ice cream flavor that is not sweet enough would receive a low rating, we also expect that an ice flavor that is too sweet would also receive a low rating. This is reflected in the scatter plot of overall rating and sweetness:
# HIDDEN
sns.lmplot(x='sweetness', y='overall', data=ice, fit_reg=False)
plt.title('Overall taste rating vs. sweetness');
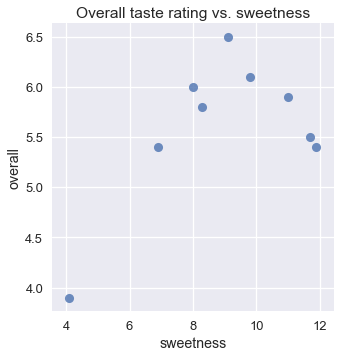
Unfortunately, a linear model alone cannot take this increase-then-decrease behavior into account; in a linear model, the overall rating can only increase or decrease monotonically with the sweetness. We can see that using linear regression results in a poor fit.
# HIDDEN
sns.lmplot(x='sweetness', y='overall', data=ice)
plt.title('Overall taste rating vs. sweetness');
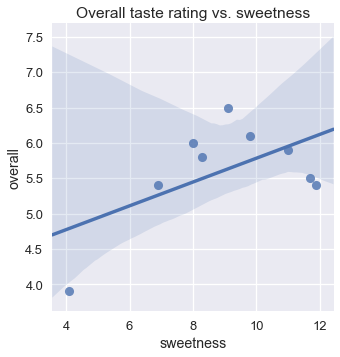
One useful approach for this problem is to fit a polynomial curve instead of line. Such a curve would allow us to model the fact that the overall rating increases with sweetness only up to a certain point, then decreases as sweetness increases.
With a feature engineering technique, we can simply add new columns to our data to use our linear model for polynomial regression.
Polynomial Features¶
Recall that in linear regression we fit one weight for each column of our data matrix $ X $. In this case, our matrix $ X $ contains two columns: a column of all ones and the sweetness.
# HIDDEN
from sklearn.preprocessing import PolynomialFeatures
first_X = PolynomialFeatures(degree=1).fit_transform(ice[['sweetness']])
pd.DataFrame(data=first_X, columns=['bias', 'sweetness'])
Our model is thus:
$$ f_\hat{\theta} (x) = \hat{\theta_0} + \hat{\theta_1} \cdot \text{sweetness} $$
We can create a new column in $ X $ containing the squared values of the sweetness.
# HIDDEN
second_X = PolynomialFeatures(degree=2).fit_transform(ice[['sweetness']])
pd.DataFrame(data=second_X, columns=['bias', 'sweetness', 'sweetness^2'])
Since our model learns one weight for each column of its input matrix, our model will become:
$$ f_\hat{\theta} (x) = \hat{\theta_0}
+ \hat{\theta_1} \cdot \text{sweetness}
+ \hat{\theta_2} \cdot \text{sweetness}^2
$$
Our model now fits a polynomial with degree two to our data. We can easily fit higher degree polynomials by adding columns for $ \text{sweetness}^3 $, $ \text{sweetness}^4 $, and so on.
Notice that this model is still a linear model because it is linear in its parameters—each $ \hat{\theta_i} $ is a scalar value of degree one. However, the model is polynomial in its features because its input data contains a column that is a polynomial transformation of another column.
Polynomial Regression¶
To conduct polynomial regression, we use a linear model with polynomial features. Thus, we import the LinearRegression model and PolynomialFeatures transform from scikit-learn.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
Our original data matrix $ X $ contains the following values. Remember that we include the column and row labels for reference purposes only; the actual $ X $ matrix only contains the numerical data in the table below.
ice[['sweetness']]
We first use the PolynomialFeatures class to transform the data, adding polynomial features of degree 2.
transformer = PolynomialFeatures(degree=2)
X = transformer.fit_transform(ice[['sweetness']])
X
Now, we fit a linear model to this data matrix.
clf = LinearRegression(fit_intercept=False)
clf.fit(X, ice['overall'])
clf.coef_
The parameters above show that for this dataset, the best-fit model is:
$$ f_\hat{\theta} (x) = -1.3 + 1.6 \cdot \text{sweetness} - 0.09 \cdot \text{sweetness}^2 $$
We can now compare this model's predictions against the original data.
# HIDDEN
sns.lmplot(x='sweetness', y='overall', data=ice, fit_reg=False)
xs = np.linspace(3.5, 12.5, 1000).reshape(-1, 1)
ys = clf.predict(transformer.transform(xs))
plt.plot(xs, ys)
plt.title('Degree 2 polynomial fit');
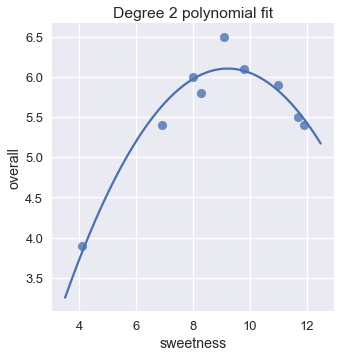
This model looks like a much better fit than our linear model. We can also verify that the mean squared cost for the degree 2 polynomial fit is much lower than the cost for the linear fit.
# HIDDEN
y = ice['overall']
pred_linear = (
LinearRegression(fit_intercept=False).fit(first_X, y).predict(first_X)
)
pred_quad = clf.predict(X)
def mse_cost(pred, y): return np.mean((pred - y) ** 2)
print(f'MSE cost for linear reg: {mse_cost(pred_linear, y):.3f}')
print(f'MSE cost for deg 2 poly reg: {mse_cost(pred_quad, y):.3f}')
Increasing the Degree¶
As mentioned earlier, we are free to add higher degree polynomial features to our data. For example, we can easily create polynomial features of degree 5:
# HIDDEN
second_X = PolynomialFeatures(degree=5).fit_transform(ice[['sweetness']])
pd.DataFrame(data=second_X,
columns=['bias', 'sweetness', 'sweetness^2', 'sweetness^3',
'sweetness^4', 'sweetness^5'])
Fitting a linear model using these features results in a degree five polynomial regression.
# HIDDEN
trans_five = PolynomialFeatures(degree=5)
X_five = trans_five.fit_transform(ice[['sweetness']])
clf_five = LinearRegression(fit_intercept=False).fit(X_five, y)
sns.lmplot(x='sweetness', y='overall', data=ice, fit_reg=False)
xs = np.linspace(3.5, 12.5, 1000).reshape(-1, 1)
ys = clf_five.predict(trans_five.transform(xs))
plt.plot(xs, ys)
plt.title('Degree 5 polynomial fit');
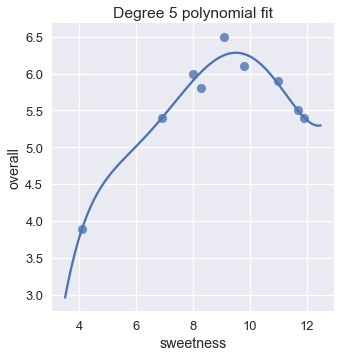
The plot shows that a degree five polynomial seems to fit the data roughly as well as a degree two polynomial. In fact, the mean squared cost for the degree five polynomial is almost half of the cost for the degree two polynomial.
pred_five = clf_five.predict(X_five)
print(f'MSE cost for linear reg: {mse_cost(pred_linear, y):.3f}')
print(f'MSE cost for deg 2 poly reg: {mse_cost(pred_quad, y):.3f}')
print(f'MSE cost for deg 5 poly reg: {mse_cost(pred_five, y):.3f}')
This suggests that we might do even better by increasing the degree even more. Why not a degree 10 polynomial?
# HIDDEN
trans_ten = PolynomialFeatures(degree=10)
X_ten = trans_ten.fit_transform(ice[['sweetness']])
clf_ten = LinearRegression(fit_intercept=False).fit(X_ten, y)
sns.lmplot(x='sweetness', y='overall', data=ice, fit_reg=False)
xs = np.linspace(3.5, 12.5, 1000).reshape(-1, 1)
ys = clf_ten.predict(trans_ten.transform(xs))
plt.plot(xs, ys)
plt.title('Degree 10 polynomial fit')
plt.ylim(3, 7);
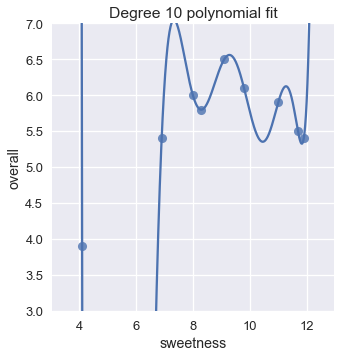
Here are the mean squared costs for the regression models we've seen thus far:
# HIDDEN
pred_ten = clf_ten.predict(X_ten)
print(f'MSE cost for linear reg: {mse_cost(pred_linear, y):.3f}')
print(f'MSE cost for deg 2 poly reg: {mse_cost(pred_quad, y):.3f}')
print(f'MSE cost for deg 5 poly reg: {mse_cost(pred_five, y):.3f}')
print(f'MSE cost for deg 10 poly reg: {mse_cost(pred_ten, y):.3f}')
The degree 10 polynomial has a cost of zero! This makes sense if we take a closer look at the plot; the degree ten polynomial manages to pass through the precise location of each point in the data.
However, you should feel hesitant to use the degree 10 polynomial to predict ice cream ratings. Intuitively, the degree 10 polynomial seems to fit our specific set of data too closely. If we take another set of data and plot them on the scatter plot above, we can expect that they fall close to our original set of data. When we do this, however, the degree 10 polynomial suddenly seems like a poor fit while the degree 2 polynomial still looks reasonable.
# HIDDEN
# sns.lmplot(x='sweetness', y='overall', data=ice, fit_reg=False)
np.random.seed(1)
x_devs = np.random.normal(scale=0.4, size=len(ice))
y_devs = np.random.normal(scale=0.4, size=len(ice))
plt.figure(figsize=(10, 5))
# Degree 10
plt.subplot(121)
ys = clf_ten.predict(trans_ten.transform(xs))
plt.plot(xs, ys)
plt.scatter(ice['sweetness'] + x_devs,
ice['overall'] + y_devs,
c='g')
plt.title('Degree 10 poly, second set of data')
plt.ylim(3, 7);
plt.subplot(122)
ys = clf.predict(transformer.transform(xs))
plt.plot(xs, ys)
plt.scatter(ice['sweetness'] + x_devs,
ice['overall'] + y_devs,
c='g')
plt.title('Degree 2 poly, second set of data')
plt.ylim(3, 7);
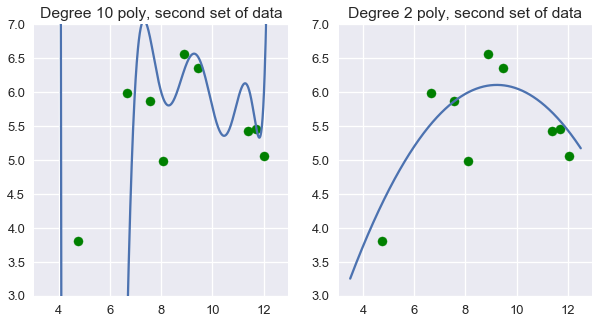
We can see that in this case, degree two polynomial features work better than both no transformation and degree ten polynomial features.
This raises the natural question: in general, how do we determine which degree polynomial to fit? Although we are tempted to use the cost on the training dataset to pick the best polynomial, we have seen that using this cost can pick a model that is too complex. Instead, we want to evaluate our model on data that is not used to fit parameters.
Summary¶
In this section, we introduce another feature engineering technique: adding polynomial features to the data in order to perform polynomial regression. Like one-hot encoding, adding polynomial features allows us to use our linear regression model effectively on more types of data.
We have also encountered a fundamental issue with feature engineering. Adding many features to the data gives the model a lower cost on its original set of data but often results in a less accurate model on new sets of data.