# HIDDEN
# Clear previously defined variables
%reset -f
# Set directory for data loading to work properly
import os
os.chdir(os.path.expanduser('~/notebooks/01'))
# HIDDEN
import warnings
# Ignore numpy dtype warnings. These warnings are caused by an interaction
# between numpy and Cython and can be safely ignored.
# Reference: https://stackoverflow.com/a/40846742
warnings.filterwarnings("ignore", message="numpy.dtype size changed")
warnings.filterwarnings("ignore", message="numpy.ufunc size changed")
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
%matplotlib inline
import ipywidgets as widgets
from ipywidgets import interact, interactive, fixed, interact_manual
import nbinteract as nbi
sns.set()
sns.set_context('talk')
np.set_printoptions(threshold=20, precision=2, suppress=True)
pd.options.display.max_rows = 7
pd.options.display.max_columns = 8
pd.set_option('precision', 2)
# This option stops scientific notation for pandas
# pd.set_option('display.float_format', '{:.2f}'.format)
# HIDDEN
students = pd.read_csv('roster.csv')
students['Name'] = students['Name'].str.lower()
What's in a Name?¶
So far, we have asked a broad question about our data: "Do the first names of students in Data 100 tell us anything about the class?"
We have cleaned our data by converting all our names to lowercase. During our exploratory data analysis we discovered that our roster contains about 270 names of students in the class and on the waitlist. Most of our first names are between 4 and 8 characters long.
What else can we discover about our class based on their first names? We might consider a single name from our dataset:
students['Name'][5]
From this name we can infer that the student is likely a male. We can also take a guess at the student's age. For example, if we happen to know that Jerry was a very popular baby name in 1998, we might guess that this student is around twenty years old.
This thinking gives us two new questions to investigate:
- "Do the first names of students in Data 100 tell us the distribution of sex in the class?"
- "Do the first names of students in Data 100 tell us the distribution of ages in the class?"
In order to investigate these questions, we will need a dataset that associates names with sex and year. Conveniently, the US Social Security department hosts such a dataset online (https://www.ssa.gov/oact/babynames/index.html). Their dataset records the names given to babies at birth and is thus often referred to as the Baby Names dataset.
We will start by downloading and then loading the dataset into Python. Again, don't worry about understanding the code in this this chapter—focus instead on understanding the overall process.
import urllib.request
import os.path
data_url = "https://www.ssa.gov/oact/babynames/names.zip"
local_filename = "babynames.zip"
if not os.path.exists(local_filename): # if the data exists don't download again
with urllib.request.urlopen(data_url) as resp, open(local_filename, 'wb') as f:
f.write(resp.read())
import zipfile
babynames = []
with zipfile.ZipFile(local_filename, "r") as zf:
data_files = [f for f in zf.filelist if f.filename[-3:] == "txt"]
def extract_year_from_filename(fn):
return int(fn[3:7])
for f in data_files:
year = extract_year_from_filename(f.filename)
with zf.open(f) as fp:
df = pd.read_csv(fp, names=["Name", "Sex", "Count"])
df["Year"] = year
babynames.append(df)
babynames = pd.concat(babynames)
babynames
It looks like the dataset contains names, the sex given to the baby, the number of babies with that name, and the year of birth for those babies. To be sure, we check the dataset description from the SSN Office (https://www.ssa.gov/oact/babynames/background.html).
All names are from Social Security card applications for births that occurred in the United States after 1879. Note that many people born before 1937 never applied for a Social Security card, so their names are not included in our data. For others who did apply, our records may not show the place of birth, and again their names are not included in our data.
All data are from a 100% sample of our records on Social Security card applications as of March 2017.
We begin by plotting the number of male and female babies born each year:
pivot_year_name_count = pd.pivot_table(
babynames, index='Year', columns='Sex',
values='Count', aggfunc=np.sum)
pink_blue = ["#E188DB", "#334FFF"]
with sns.color_palette(sns.color_palette(pink_blue)):
pivot_year_name_count.plot(marker=".")
plt.title("Registered Names vs Year Stratified by Sex")
plt.ylabel('Names Registered that Year')
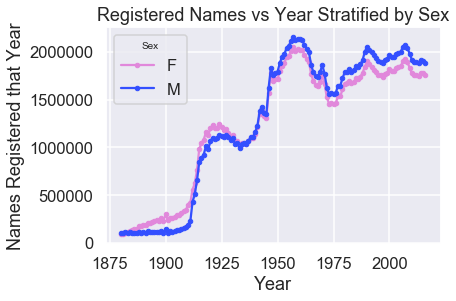
The meteoric rise in babies born in the years leading up to 1920 may seem suspicious. A sentence from the quote above helps explain:
Note that many people born before 1937 never applied for a Social Security card, so their names are not included in our data. For others who did apply, our records may not show the place of birth, and again their names are not included in our data.
We can also see the baby boomer period quite clearly in the plot above.
Inferring Sex From Name¶
Let's use this dataset to estimate the number of females and males in our class. As with our class roster, we begin by lowercasing the names:
babynames['Name'] = babynames['Name'].str.lower()
babynames
Then, we count up how many male and female babies were born in total for each name:
sex_counts = pd.pivot_table(babynames, index='Name', columns='Sex', values='Count',
aggfunc='sum', fill_value=0., margins=True)
sex_counts
To determine whether a name is more popular for male or female babies, we can compute the proportion of times the name was given to a female baby.
prop_female = sex_counts['F'] / sex_counts['All']
sex_counts['prop_female'] = prop_female
sex_counts
We can then define a function that looks up the proportion of female names given a name.
def sex_from_name(name):
if name in sex_counts.index:
prop = sex_counts.loc[name, 'prop_female']
return 'F' if prop > 0.5 else 'M'
else:
return 'Name not in dataset'
sex_from_name('sam')
Our First Widget¶
In this book, we include widgets that allow the reader to interact with functions defined in the book. The widget below displays the output of sex_from_name on a reader-provided name.
Try typing in the name "josephine" and see how the inferred sex changes as more characters are entered.
interact(sex_from_name, name='sam');
We mark each name in our class roster with its most likely sex.
students['sex'] = students['Name'].apply(sex_from_name)
students
Now it is easy to estimate how many male and female students we have:
students['sex'].value_counts()
Inferring Age From Name¶
We can proceed in a similar way to estimate the age distribution of the class, mapping each name to its average age in the dataset.
def avg_year(group):
return np.average(group['Year'], weights=group['Count'])
avg_years = (
babynames
.groupby('Name')
.apply(avg_year)
.rename('avg_year')
.to_frame()
)
avg_years
As before, we define a function to lookup the average birth year using a given name. We've included a widget for the reader to try out some names. We suggest trying names that seem older (e.g. "Mary") and names that seem newer (e.g. "Beyonce").
def year_from_name(name):
return (avg_years.loc[name, 'avg_year']
if name in avg_years.index
else None)
# Generate input box for you to try some names out:
interact(year_from_name, name='fernando');
Now, we can mark each name in Data 100 with its inferred birth year.
students['year'] = students['Name'].apply(year_from_name)
students
Then, it is easy to plot the distribution of years:
sns.distplot(students['year'].dropna());
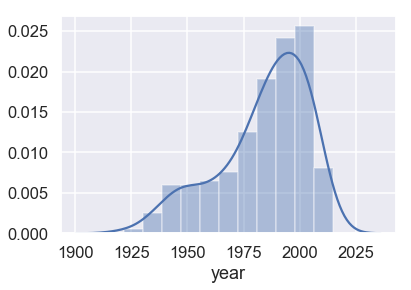
To compute the average year:
students['year'].mean()
Our class has an average age of 35 years old—nearly twice our expected age in a course for college undergraduates. Why might our estimate be so far off?
As data scientists, we often run into results that don't agree with our expectations. Our constant challenge is to determine whether surprising results are caused by an error in our procedure or by an actual, real-world phenomenon. Since there are no simple recipes to guarantee accurate conclusions, data scientists must equip themselves with guidelines and principles to reduce the likelihood of false discovery.
In this particular case, the most likely explanation for our unexpected result is that most common names have been used for many years. For example, the name John was quite popular throughout the history recorded in our data. We can confirm this by plotting the number of babies given the name "John" each year:
names = babynames.set_index('Name').sort_values('Year')
john = names.loc['john']
john[john['Sex'] == 'M'].plot('Year', 'Count')
plt.title('Frequency of "John"');
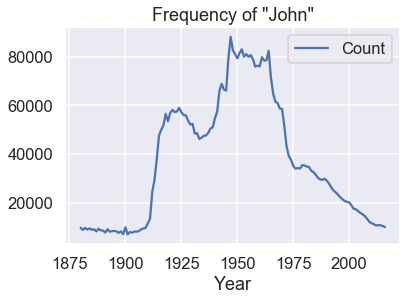
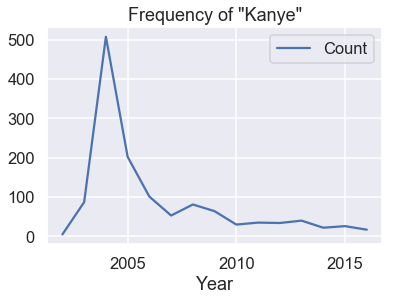
It appears that the average birth year does not provide an accurate estimate for a given person's age in general. In a few cases, however, a person's first name is quite revealing!
names = babynames.set_index('Name').sort_values('Year')
kanye = names.loc['kanye']
kanye[kanye['Sex'] == 'M'].plot('Year', 'Count')
plt.title('Frequency of "Kanye"');
Summary¶
In this chapter, we walk through a complete iteration of the data science lifecycle: question formulation, data manipulation, exploratory data analysis, and prediction. We expand upon each of these steps in the following chapters.
The first half of the book (chapters 1-9) broadly covers the first three steps in the lifecycle and has a strong focus on computation. The second half of the book (chapters 10-18) uses both computational and statistical thinking to cover modeling, inference, and prediction.
As a whole, this book hopes to impart the reader with the principles and techniques of data science.