# HIDDEN
# Clear previously defined variables
%reset -f
# Set directory for data loading to work properly
import os
os.chdir(os.path.expanduser('~/notebooks/17'))
# HIDDEN
import warnings
# Ignore numpy dtype warnings. These warnings are caused by an interaction
# between numpy and Cython and can be safely ignored.
# Reference: https://stackoverflow.com/a/40846742
warnings.filterwarnings("ignore", message="numpy.dtype size changed")
warnings.filterwarnings("ignore", message="numpy.ufunc size changed")
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
%matplotlib inline
import ipywidgets as widgets
from ipywidgets import interact, interactive, fixed, interact_manual
import nbinteract as nbi
sns.set()
sns.set_context('talk')
np.set_printoptions(threshold=20, precision=2, suppress=True)
pd.options.display.max_rows = 7
pd.options.display.max_columns = 8
pd.set_option('precision', 2)
# This option stops scientific notation for pandas
# pd.set_option('display.float_format', '{:.2f}'.format)
# HIDDEN
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
emails=pd.read_csv('selected_emails.csv', index_col=0)
# HIDDEN
def words_in_texts(words, texts):
'''
Args:
words (list-like): words to find
texts (Series): strings to search in
Returns:
NumPy array of 0s and 1s with shape (n, p) where n is the
number of texts and p is the number of words.
'''
indicator_array = np.array([texts.str.contains(word) * 1 for word in words]).T
# YOUR CODE HERE
return indicator_array
Evaluating Logistic Models¶
Although we used the classification accuracy to evaluate our logistic model in previous sections, using the accuracy alone has some serious flaws that we explore in this section. To address these issues, we introduce a more useful metric to evaluate classifier performance: the Area Under Curve (AUC) metric.
Suppose we have a dataset of 1000 emails that are labeled as spam or ham (not spam) and our goal is to build a classifier that distinguishes future spam emails from ham emails. The data is contained in the emails DataFrame displayed below:
emails
Each row contains the body of an email in the body column and a spam indicator in the spam column, which is 0 if the email is ham or 1 if it is spam.
Let's compare the performance of three different classifiers:
ham_only: labels every email as ham.spam_only: labels every email as spam.words_list_model: predicts 'ham' or 'spam' based on the presence of certain words in the body of an email.
Suppose we have a list of words words_list that we believe are common in spam emails: "please", "click", "money", "business", and "remove". We construct words_list_model using the following procedure: transform each email into a feature vector by setting the vector's $i$th entry to 1 if the $i$th word in words_list is contained in the email body and 0 if it isn't. For example, using our five chosen words and the email body "please remove by tomorrow", the feature vector would be $[1, 0, 0, 0, 1]$. This procedure generates the 1000 X 5 feature matrix $\textbf{X}$.
The following code block displays the accuracies of the classifiers. Model creation and training are omitted for brevity.
# HIDDEN
words_list = ['please', 'click', 'money', 'business', 'remove']
X = pd.DataFrame(words_in_texts(words_list, emails['body'].str.lower())).as_matrix()
y = emails['spam'].as_matrix()
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state=41, test_size=0.2
)
#Fit the model
words_list_model = LogisticRegression(fit_intercept=True)
words_list_model.fit(X_train, y_train)
y_prediction_words_list = words_list_model.predict(X_test)
y_prediction_ham_only = np.zeros(len(y_test))
y_prediction_spam_only = np.ones(len(y_test))
from sklearn.metrics import accuracy_score
# Our selected words
words_list = ['please', 'click', 'money', 'business']
print(f'ham_only test set accuracy: {np.round(accuracy_score(y_prediction_ham_only, y_test), 3)}')
print(f'spam_only test set accuracy: {np.round(accuracy_score(y_prediction_spam_only, y_test), 3)}')
print(f'words_list_model test set accuracy: {np.round(accuracy_score(y_prediction_words_list, y_test), 3)}')
Using words_list_model classifies 96% of the test set emails correctly. Although this accuracy appears high, ham_only achieves the same accuracy by simply labeling everything as ham. This is cause for concern because the data suggests we can do just as well without a spam filter at all.
As the accuracies above show, model accuracy alone can be a misleading indicator of model performance. We can understand the model's predictions in greater depth using a confusion matrix. A confusion matrix for a binary classifier is a two-by-two heatmap that contains the model predictions on one axis and the actual labels on the other.
Each entry in a confusion matrix represents a possible outcome of the classifier. If a spam email is input to the classifier, there are two possible outcomes:
- True Positive (top left entry): the model correctly labels it with the positive class (spam).
- False Negative (top right entry): the model mislabels it with the negative class (ham), but it truly belongs in the positive class (spam). In our case, a false negative means that a spam email gets mislabelled as ham and ends up in the inbox.
Similarly, if a ham email is input to the classifier, there are two possible outcomes.
- False Positive (bottom left entry): the model mislabels it with the positive class (spam), but it truly belongs in the negative class (ham). In our case, a false positive means that a ham email gets flagged as spam and filtered out of the inbox.
- True Negative (bottom right entry): the model correctly labels it with the negative class (ham).
The costs of false positives and false negatives depend on the situation. For email classification, false positives result in important emails being filtered out, so they are worse than false negatives, in which a spam email winds up in the inbox. In medical settings, however, false negatives in a diagnostic test can be much more consequential than false positives.
We will use scikit-learn's confusion matrix function to construct confusion matrices for the three models on the training data set. The ham_only confusion matrix is shown below:
# HIDDEN
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
import itertools
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
# print("Normalized confusion matrix")
# else:
# print('Confusion matrix, without normalization')
# print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.grid(False)
ham_only_y_pred = np.zeros(len(y_train))
spam_only_y_pred = np.ones(len(y_train))
words_list_model_y_pred = words_list_model.predict(X_train)
from sklearn.metrics import confusion_matrix
class_names = ['Spam', 'Ham']
ham_only_cnf_matrix = confusion_matrix(y_train, ham_only_y_pred, labels=[1, 0])
plot_confusion_matrix(ham_only_cnf_matrix, classes=class_names,
title='ham_only Confusion Matrix')
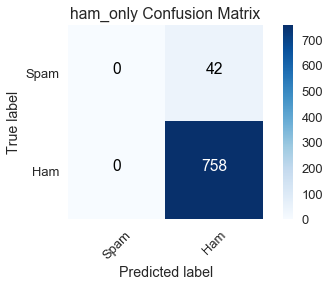
Summing the quantities in a row indicates how many emails in the training dataset belong to the corresponding class:
- True label = spam (first row): the sum of true positives (0) and false negatives (42) reveals there are 42 spam emails in the training dataset.
- True label = ham (second row): the sum of false positives (0) and true negatives (758) reveals there are 758 ham emails in the training dataset.
Summing the quantities in a column indicates how many emails the classifier predicted in the corresponding class:
- Predicted label = spam (first column): the sum of true positives (0) and false positives (0) reveals
ham_onlypredicted there are 0 spam emails in the training dataset. - Predicted label = ham (second column): the sum of false negatives (42) and true negatives (758) reveals
ham_onlypredicted there are 800 ham emails in the training dataset.
We can see that ham_only had a high accuracy of $\left(\frac{758}{800} \approx .95\right)$ because there are 758 ham emails in the training dataset out of 800 total emails.
spam_only_cnf_matrix = confusion_matrix(y_train, spam_only_y_pred, labels=[1, 0])
plot_confusion_matrix(spam_only_cnf_matrix, classes=class_names,
title='spam_only Confusion Matrix')
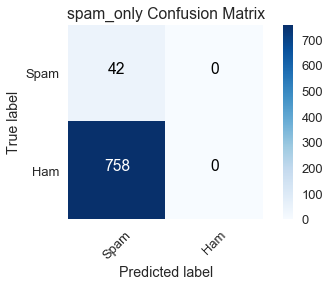
At the other extreme, spam_only predicts the training dataset has no ham emails, which the confusion matrix indicates is far from the truth with 758 false positives.
Our main interest is the confusion matrix for words_list_model:
words_list_model_cnf_matrix = confusion_matrix(y_train, words_list_model_y_pred, labels=[1, 0])
plot_confusion_matrix(words_list_model_cnf_matrix, classes=class_names,
title='words_list_model Confusion Matrix')
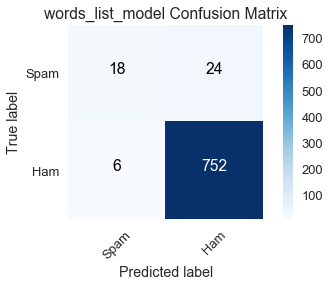
The row totals match those of the ham_only and spam_only confusion matrices as expected since the true labels in the training dataset are unaltered for all models.
Of the 42 spam emails, words_list_model correctly classifies 18 of them, which is a poor performance. Its high accuracy is buoyed by the large number of true negatives, but this is insufficient because it does not serve its purpose of reliably filtering out spam emails.
This emails dataset is an example of a class-imbalanced dataset, in which a vast majority of labels belong to one class over the other. In this case, most of our emails are ham. Another common example of class imbalance is disease detection when the frequency of the disease in a population is low. A medical test that always concludes a patient doesn't have the disease will have a high accuracy because most patients truly won't have the disease, but its inability to identify individuals with the disease renders it useless.
We now turn to sensitivity and specificity, two metrics that are better suited for evaluating class-imbalanced datasets.
Sensitivity¶
Sensitivity (also called true positive rate) measures the proportion of data belonging to the positive class that the classifier correctly labels.
$$ \text{Sensitivity} = \frac{TP}{TP + FN} $$
From our discussion of confusion matrices, you should recognize the expression $TP + FN$ as the sum of the entries in the first row, which is equal to the actual number of data points belonging to the positive class in the dataset. Using confusion matrices allows us to easily compare the sensitivities of our models:
ham_only: $\frac{0}{0 + 42} = 0$spam_only: $\frac{42}{42 + 0} = 1$words_list_model: $\frac{18}{18 + 24} \approx .429$
Since ham_only has no true positives, it has the worst possible sensitivity value of 0. On the other hand, spam_only has an abysmally low accuracy but it has the best possible sensitivity value of 1 because it labels all spam emails correctly. The low sensitivity of words_list_model indicates that it frequently fails to mark spam emails as such; nevertheless, it significantly outperforms ham_only.
Specificity¶
Specificity (also called true negative rate) measures the proportion of data belonging to the negative class that the classifier correctly labels.
$$ \text{Specificity} = \frac{TN}{TN + FP} $$
The expression $TN + FP$ is equal to the actual number of data points belonging to the negative class in the dataset. Again the confusion matrices help to compare the specificities of our models:
ham_only: $\frac{758}{758 + 0} = 1$spam_only: $\frac{0}{0 + 758} = 0$words_list_model: $\frac{752}{752 + 6} \approx .992$
As with sensitivity, the worst and best specificities are 0 and 1 respectively. Notice that ham_only has the best specificity and worst sensitivity, while spam_only has the worst specificity and best sensitivity. Since these models only predict one label, they will misclassify all instances of the other label, which is reflected in the extreme sensitivity and specificity values. The disparity is much smaller for words_list_model.
Although sensitivity and specificity seem to describe different characteristics of a classifier, we draw an important connection between these two metrics using the classification threshold.
Classification Threshold¶
The classification threshold is a value that determines what class a data point is assigned to; points that fall on opposite sides of the threshold are labeled with different classes. Recall that logistic regression outputs a probability that the data point belongs to the positive class. If this probability is greater than the threshold, the data point is labeled with the positive class, and if it is below the threshold, the data point is labeled with the negative class. For our case, let $f_{\hat{\theta}}$ be the logistic model and $C$ the threshold. If $f_{\hat{\theta}}(x) > C$, $x$ is labeled spam; if $f_{\hat{\theta}}(x) < C$, $x$ is labeled ham. Scikit-learn breaks ties by defaulting to the negative class, so if $f_{\hat{\theta}}(x) = C$, $x$ is labeled ham.
We can assess our model's performance with classification threshold $C$ by creating a confusion matrix. The words_list_model confusion matrix displayed earlier in the section uses scikit learn's default threshold $C = .50$.
Raising the threshold to $C = .70$, meaning we label an email $x$ as spam if the probability $f_{\hat{\theta}}(x)$ is greater than .70, results in the following confusion matrix:
# HIDDEN
words_list_prediction_probabilities = words_list_model.predict_proba(X_train)[:, 1]
words_list_predictions = [1 if pred >= .70 else 0 for pred in words_list_prediction_probabilities]
high_classification_threshold = confusion_matrix(y_train, words_list_predictions, labels=[1, 0])
plot_confusion_matrix(high_classification_threshold, classes=class_names,
title='words_list_model Confusion Matrix $C = .70$')
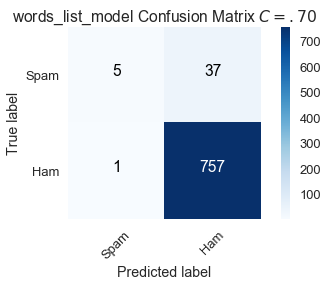
By raising the bar for classifying an email as spam, 13 spam emails that were correctly classified with $C = .50$ are now mislabeled.
$$ \text{Sensitivity } (C = .70) = \frac{5}{42} \approx .119 \\ \text{Specificity } (C = .70) = \frac{757}{758} \approx .999 $$
Compared to the default, a higher threshold of $C = .70$ increases specificity but decreases sensitivity.
Lowering the threshold to $C = .30$, meaning we label an email $x$ as spam if the probability $f_{\hat{\theta}}(x)$ is greater than .30, results in the following confusion matrix:
# HIDDEN
words_list_predictions = [1 if pred >= .30 else 0 for pred in words_list_prediction_probabilities]
low_classification_threshold = confusion_matrix(y_train, words_list_predictions, labels=[1, 0])
plot_confusion_matrix(low_classification_threshold, classes=class_names,
title='words_list_model Confusion Matrix $C = .30$')
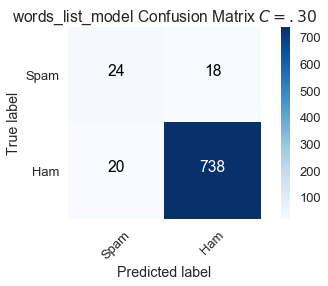
By lowering the bar for classifying an email as spam, 6 spam emails that were mislabeled with $C = .50$ are now correct. However, there are more false positives.
$$ \text{Sensitivity } (C = .30) = \frac{24}{42} \approx .571 \\ \text{Specificity } (C = .30) = \frac{738}{758} \approx .974 $$
Compared to the default, a lower threshold of $C = .30$ increases sensitivity but decreases specificity.
We adjust a model's sensitivity and specificity by changing the classification threshold. Although we strive to maximize both sensitivity and specificity, we can see from the confusion matrices created with varying classification thresholds that there is a tradeoff. Increasing sensitivity leads to a decrease in specificity and vice versa.
ROC Curves¶
We can calculate sensitivity and specificity values for all classification thresholds between 0 and 1 and plot them. Each threshold value $C$ is associated with a (sensitivity, specificity) pair. A ROC (Receiver Operating Characteristic) curve is a slight modification of this idea; instead of plotting (sensitivity, specificity) it plots (sensitivity, 1 - specificity) pairs, where 1 - specificity is defined as the false positive rate.
$$ \text{False Positive Rate } = 1 - \frac{TN}{TN + FP} = \frac{TN + FP - TN}{TN + FP} = \frac{FP}{TN + FP} $$
A point on the ROC curve represents the sensitivity and false positive rate associated with a specific threshold value.
The ROC curve for words_list_model is calculated below using scikit-learn's ROC curve function:
from sklearn.metrics import roc_curve
words_list_model_probabilities = words_list_model.predict_proba(X_train)[:, 1]
false_positive_rate_values, sensitivity_values, thresholds = roc_curve(y_train, words_list_model_probabilities, pos_label=1)
# HIDDEN
plt.step(false_positive_rate_values, sensitivity_values, color='b', alpha=0.2,
where='post')
plt.xlabel('False Positive Rate (1 - Specificity)')
plt.ylabel('Sensitivity')
plt.title('words_list_model ROC Curve')
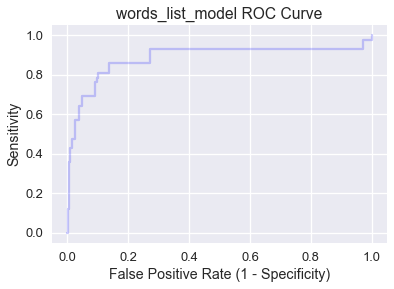
Notice that as we move from left to right across the curve, sensitivity increases and the specificity decreases. Generally, the best classification threshold corresponds to high sensitivity and specificity (low false positive rate), so points in or around the northwest corner of the plot are preferable.
Let's examine the four corners of the plot:
- (0, 0): Specificity $=1$, which means all data points in the negative class are correctly labeled, but sensitivity $= 0$, so the model has no true positives. (0,0) maps to the classification threshold $C = 1.0$, which has the same effect as
ham_onlysince no email can have a probability greater than $1.0$. - (1, 1): Specificity $=0$, which means the model has no true negatives, but sensitivity $= 1$, so all data points in the positive class are correctly labeled. (1,1) maps to the classification threshold $C = 0.0$, which has the same effect as
spam_onlysince no email can have a probability lower than $0.0$. - (0, 1): Both specificity $=1$ and sensitivity $= 1$, which means there are no false positives or false negatives. A model with an ROC curve containing (0, 1) has a $C$ value at which it is a perfect classifier!
- (1, 0): Both specificity $=0$ and sensitivity $= 0$, which means there are no true positives or true negatives. A model with an ROC curve containing (1, 0) has a $C$ value at which it predicts the wrong class for every data point!
A classifier that randomly predicts classes has a diagonal ROC curve containing all points where sensitivity and the false positive rate are equal:
# HIDDEN
plt.step(np.arange(0, 1, 0.001), np.arange(0, 1, 0.001), color='b', alpha=0.2,
where='post')
plt.xlabel('False Positive Rate (1 - Specificity)')
plt.ylabel('Sensitivity')
plt.title('Random Classifier ROC Curve')
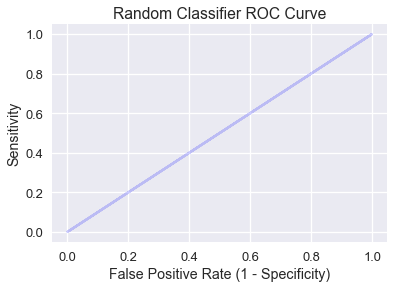
Intuitively, a random classifier that predicts probability $p$ for input $x$ will result in either a true positive or false positive with chance $p$, so sensitivity and the false positive rate are equal.
We want our classifier's ROC curve to be high above the random model diagnoal line, which brings us to the AUC metric.
AUC¶
The Area Under Curve (AUC) is the area under the ROC curve and serves as a single number performance summary of the classifier. The AUC for words_list_model is shaded below and calculating using scikit-learn's AUC function:
# HIDDEN
plt.fill_between(false_positive_rate_values, sensitivity_values, step='post', alpha=0.2,
color='b')
plt.xlabel('False Positive Rate (1 - Specificity)')
plt.ylabel('Sensitivity')
plt.title('words_list_model ROC Curve')
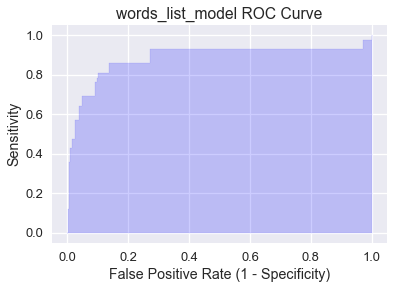
from sklearn.metrics import roc_auc_score
roc_auc_score(y_train, words_list_model_probabilities)
AUC is interpreted as the probability that the classifier will assign a higher probability to a randomly chosen data point truly belonging to the positive class than a randomly chosen data point truly belonging to the negative class. A perfect AUC value of 1 corresponds to a perfect classifier (the ROC curve would contain (0, 1). The fact that words_list_model has an AUC of .906 means that roughly 90.6% of the time it is more likely to classify a spam email as spam than a ham email as spam.
By inspection, the AUC of the random classifier is 0.5, though this can vary slightly due to the randomness. An effective model will have an AUC much higher than 0.5, which words_list_model achieves. If a model's AUC is less than 0.5, it performs worse than random predictions.
Summary¶
AUC is an essential metric for evaluating models on class-imbalanced datasets. After training a model, it is best practice to generate an ROC curve and calculate AUC to determine the next step. If the AUC is sufficiently high, use the ROC curve to identify the best classification threshold. However, if the AUC is not satisfactory, consider doing further EDA and feature selection to improve the model.