# HIDDEN
# Clear previously defined variables
%reset -f
# Set directory for data loading to work properly
import os
os.chdir(os.path.expanduser('~/notebooks/11'))
# HIDDEN
import warnings
# Ignore numpy dtype warnings. These warnings are caused by an interaction
# between numpy and Cython and can be safely ignored.
# Reference: https://stackoverflow.com/a/40846742
warnings.filterwarnings("ignore", message="numpy.dtype size changed")
warnings.filterwarnings("ignore", message="numpy.ufunc size changed")
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
%matplotlib inline
import ipywidgets as widgets
from ipywidgets import interact, interactive, fixed, interact_manual
import nbinteract as nbi
sns.set()
sns.set_context('talk')
np.set_printoptions(threshold=20, precision=2, suppress=True)
pd.options.display.max_rows = 7
pd.options.display.max_columns = 8
pd.set_option('precision', 2)
# This option stops scientific notation for pandas
# pd.set_option('display.float_format', '{:.2f}'.format)
# HIDDEN
tips = sns.load_dataset('tips')
tips['pcttip'] = tips['tip'] / tips['total_bill'] * 100
# HIDDEN
def mse(theta, y_vals):
return np.mean((y_vals - theta) ** 2)
def grad_mse(theta, y_vals):
return -2 * np.mean(y_vals - theta)
def plot_loss(y_vals, xlim, loss_fn):
thetas = np.arange(xlim[0], xlim[1] + 0.01, 0.05)
losses = [loss_fn(theta, y_vals) for theta in thetas]
plt.figure(figsize=(5, 3))
plt.plot(thetas, losses, zorder=1)
plt.xlim(*xlim)
plt.title(loss_fn.__name__)
plt.xlabel(r'$ \theta $')
plt.ylabel('Loss')
def plot_theta_on_loss(y_vals, theta, loss_fn, **kwargs):
loss = loss_fn(theta, y_vals)
default_args = dict(label=r'$ \theta $', zorder=2,
s=200, c=sns.xkcd_rgb['green'])
plt.scatter([theta], [loss], **{**default_args, **kwargs})
def plot_tangent_on_loss(y_vals, theta, loss_fn, eps=1e-6):
slope = ((loss_fn(theta + eps, y_vals) - loss_fn(theta - eps, y_vals))
/ (2 * eps))
xs = np.arange(theta - 1, theta + 1, 0.05)
ys = loss_fn(theta, y_vals) + slope * (xs - theta)
plt.plot(xs, ys, zorder=3, c=sns.xkcd_rgb['green'], linestyle='--')
Gradient Descent¶
We are interested in creating a function that can minimize a loss function without forcing the user to predetermine which values of $\theta$ to try. In other words, while the simple_minimize function has the following signature:
simple_minimize(loss_fn, dataset, thetas)
We would like a function that has the following signature:
minimize(loss_fn, dataset)
This function needs to automatically find the minimizing $\theta$ value no matter how small or large it is. We will use a technique called gradient descent to implement this new minimize function.
Intuition¶
As with loss functions, we will discuss the intuition for gradient descent first, then formalize our understanding with mathematics.
Since the minimize function is not given values of $\theta$ to try, we start by picking a $\theta$ anywhere we'd like. Then, we can iteratively improve the estimate of $\theta$. To improve an estimate of $\theta$, we look at the slope of the loss function at that choice of $ \theta $.
For example, suppose we are using MSE for the simple dataset $ \textbf{y} = [ 12.1, 12.8, 14.9, 16.3, 17.2 ] $ and our current choice of $ \theta $ is 12.
# HIDDEN
pts = np.array([12.1, 12.8, 14.9, 16.3, 17.2])
plot_loss(pts, (11, 18), mse)
plot_theta_on_loss(pts, 12, mse)
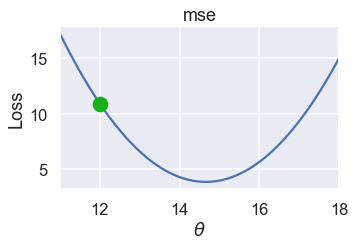
We'd like to choose a new value for $\theta$ that decreases the loss. To do this, we look at the slope of the loss function at $\theta= 12 $:
# HIDDEN
pts = np.array([12.1, 12.8, 14.9, 16.3, 17.2])
plot_loss(pts, (11, 18), mse)
plot_tangent_on_loss(pts, 12, mse)
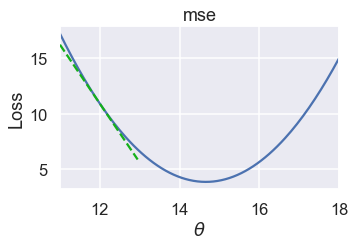
The slope is negative, which means that increasing $\theta$ will decrease the loss.
If $\theta = 16.5 $ on the other hand, the slope of the loss function is positive:
# HIDDEN
pts = np.array([12.1, 12.8, 14.9, 16.3, 17.2])
plot_loss(pts, (11, 18), mse)
plot_tangent_on_loss(pts, 16.5, mse)
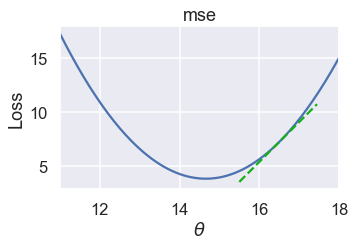
When the slope is positive, decreasing $ \theta $ will decrease the loss.
The slope of the tangent line tells us which direction to move $ \theta $ in order to decrease the loss. If the slope is negative, we want $ \theta $ to move in the positive direction. If the slope is positive, $\theta $ should move in the negative direction. Mathematically, we write:
$$ \theta^{(t+1)} = \theta^{(t)} - \frac{\partial}{\partial \theta} L(\theta^{(t)}, \textbf{y}) $$
Where $ \theta^{(t)} $ is the current estimate and $ \theta^{(t+1)} $ is the next estimate.
For the MSE, we have:
$$ \begin{aligned} L(\theta, \textbf{y}) &= \frac{1}{n} \sum_{i = 1}^{n}(y_i - \theta)^2\\ \frac{\partial}{\partial \hat{\theta}} L(\theta, \textbf{y}) &= \frac{1}{n} \sum_{i = 1}^{n} -2(y_i - \theta) \\ &= -\frac{2}{n} \sum_{i = 1}^{n} (y_i - \theta) \\ \end{aligned} $$
When $ \theta^{(t)} = 12 $, we can compute $ -\frac{2}{n} \sum_{i = 1}^{n} (y_i - \theta) = -5.32 $. Thus, $ \theta^{(t+1)} = 12 - (-5.32) = 17.32 $.
We've plotted the old value of $ \theta $ as a green outlined circle and the new value as a filled in circle on the loss curve below.
# HIDDEN
pts = np.array([12.1, 12.8, 14.9, 16.3, 17.2])
plot_loss(pts, (11, 18), mse)
plot_theta_on_loss(pts, 12, mse, c='none',
edgecolor=sns.xkcd_rgb['green'], linewidth=2)
plot_theta_on_loss(pts, 17.32, mse)
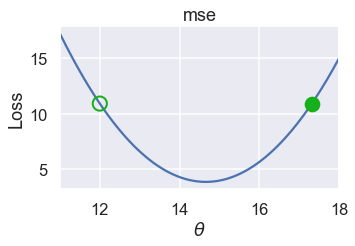
Although $ \theta $ went in the right direction, it ended up as far away from the minimum as it started. We can remedy this by multiplying the slope by a small constant before subtracting it from $ \theta$. Our final update formula is:
$$ \theta^{(t+1)} = \theta^{(t)} - \alpha \cdot \frac{\partial}{\partial \theta} L(\theta^{(t)}, \textbf{y}) $$
where $ \alpha $ is a small constant. For example, if we set $ \alpha = 0.3 $, this is the new $ \theta^{(t+1)} $:
# HIDDEN
def plot_one_gd_iter(y_vals, theta, loss_fn, grad_loss, alpha=0.3):
new_theta = theta - alpha * grad_loss(theta, y_vals)
plot_loss(pts, (11, 18), loss_fn)
plot_theta_on_loss(pts, theta, loss_fn, c='none',
edgecolor=sns.xkcd_rgb['green'], linewidth=2)
plot_theta_on_loss(pts, new_theta, loss_fn)
print(f'old theta: {theta}')
print(f'new theta: {new_theta}')
# HIDDEN
plot_one_gd_iter(pts, 12, mse, grad_mse)
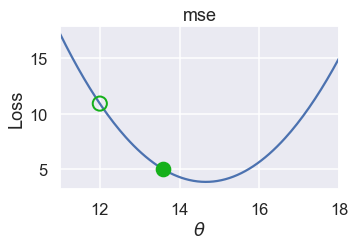
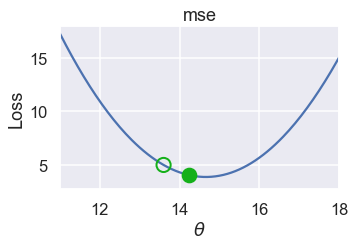
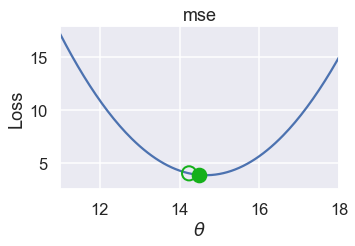
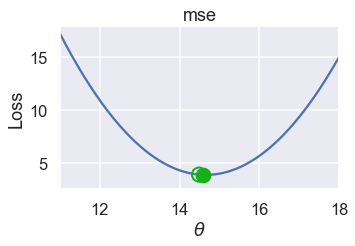
Here are the $ \theta $ values for successive iterations of this process. Notice that $ \theta $ changes more slowly as it gets closer to the minimum loss because the slope is also smaller.
# HIDDEN
plot_one_gd_iter(pts, 13.60, mse, grad_mse)
# HIDDEN
plot_one_gd_iter(pts, 14.24, mse, grad_mse)
# HIDDEN
plot_one_gd_iter(pts, 14.49, mse, grad_mse)
Gradient Descent Analysis¶
We now have the full algorithm for gradient descent:
- Choose a starting value of $ \theta $ (0 is a common choice).
- Compute $ \theta - \alpha \cdot \frac{\partial}{\partial \theta} L(\theta, \textbf{y}) $ and store this as the new value of $ \theta $.
- Repeat until $ \theta $ doesn't change between iterations.
You will more commonly see the gradient $ \nabla_\theta $ in place of the partial derivative $ \frac{\partial}{\partial \theta} $. The two notations are essentially equivalent, but since the gradient notation is more common we will use it in the gradient update formula from now on:
$$ \theta^{(t+1)} = \theta^{(t)} - \alpha \cdot \nabla_\theta L(\theta^{(t)}, \textbf{y}) $$
To review notation:
- $ \theta^{(t)} $ is the current estimate of $ \theta^* $ at the $t$th iteration.
- $ \theta^{(t+1)} $ is the next choice of $ \theta $.
- $ \alpha $ is called the learning rate, usually set to a small constant. Sometimes it is useful to start with a larger $ \alpha $ and decrease it over time. If $ \alpha $ changes between iterations, we use the variable $ \alpha^t $ to mark that $ \alpha $ varies over time $ t $.
- $ \nabla_\theta L(\theta^{(t)}, \textbf{y}) $ is the partial derivative / gradient of the loss function with respect to $ \theta $ at time $t$.
You can now see the importance of choosing a differentiable loss function: $ \nabla_\theta L(\theta, \textbf{y}) $ is a crucial part of the gradient descent algorithm. (While it is possible to estimate the gradient by computing the difference in loss for two slightly different values of $ \theta $ and dividing by the distance between $ \theta $ values, this typically increases the runtime of gradient descent so significantly that it becomes impractical to use.)
The gradient algorithm is simple yet powerful since we can use it for many types of models and many types of loss functions. It is the computational tool of choice for fitting many important models, including linear regression on large datasets and neural networks.
Defining the minimize Function¶
Now we return to our original task: defining the minimize function. We will have to change our function signature slightly since we now need to compute the gradient of the loss function.
def minimize(loss_fn, grad_loss_fn, dataset, alpha=0.2, progress=True):
'''
Uses gradient descent to minimize loss_fn. Returns the minimizing value of
theta_hat once theta_hat changes less than 0.001 between iterations.
'''
theta = 0
while True:
if progress:
print(f'theta: {theta:.2f} | loss: {loss_fn(theta, dataset):.2f}')
gradient = grad_loss_fn(theta, dataset)
new_theta = theta - alpha * gradient
if abs(new_theta - theta) < 0.001:
return new_theta
theta = new_theta
Then we can define functions to compute our MSE and its gradient:
def mse(theta, y_vals):
return np.mean((y_vals - theta) ** 2)
def grad_mse(theta, y_vals):
return -2 * np.mean(y_vals - theta)
Finally, we can use the minimize function to compute the minimizing value of $ \theta $ for $ \textbf{y} = [12.1, 12.8, 14.9, 16.3, 17.2] $.
%%time
theta = minimize(mse, grad_mse, np.array([12.1, 12.8, 14.9, 16.3, 17.2]))
print(f'Minimizing theta: {theta}')
print()
We can see that gradient descent quickly finds the same solution as the analytic method:
np.mean([12.1, 12.8, 14.9, 16.3, 17.2])
Minimizing the Huber loss¶
Now, we can apply gradient descent to minimize the Huber loss on our dataset of tip percentages.
The Huber loss is:
$$ L_\delta(\theta, \textbf{y}) = \frac{1}{n} \sum_{i=1}^n \begin{cases} \frac{1}{2}(y_i - \theta)^2 & | y_i - \theta | \le \delta \\ \delta (|y_i - \theta| - \frac{1}{2} \delta ) & \text{otherwise} \end{cases} $$
The gradient of the Huber loss is:
$$ \nabla{\theta} L\delta(\theta, \textbf{y}) = \frac{1}{n} \sum_{i=1}^n \begin{cases} -(y_i - \theta) & | y_i - \theta | \le \delta \
- \delta \cdot \text{sign} (y_i - \theta) & \text{otherwise}
\end{cases} $$
(Note that in previous definitions of Huber loss we used the variable $ \alpha $ to denote the transition point. To avoid confusion with the $ \alpha $ used in gradient descent, we replace the transition point parameter of the Huber loss with $ \delta $.)
def huber_loss(theta, dataset, delta = 1):
d = np.abs(theta - dataset)
return np.mean(
np.where(d <= delta,
(theta - dataset)**2 / 2.0,
delta * (d - delta / 2.0))
)
def grad_huber_loss(theta, dataset, delta = 1):
d = np.abs(theta - dataset)
return np.mean(
np.where(d <= delta,
-(dataset - theta),
-delta * np.sign(dataset - theta))
)
Let's minimize the Huber loss on the tips dataset:
%%time
theta = minimize(huber_loss, grad_huber_loss, tips['pcttip'], progress=False)
print(f'Minimizing theta: {theta}')
print()
Summary¶
Gradient descent gives us a generic way to minimize a loss function when we cannot solve for the minimizing value of $ \theta $ analytically. As our models and loss functions increase in complexity, we will turn to gradient descent as our tool of choice to fit models.