# HIDDEN
# Clear previously defined variables
%reset -f
# Set directory for data loading to work properly
import os
os.chdir(os.path.expanduser('~/notebooks/14'))
# HIDDEN
import warnings
# Ignore numpy dtype warnings. These warnings are caused by an interaction
# between numpy and Cython and can be safely ignored.
# Reference: https://stackoverflow.com/a/40846742
warnings.filterwarnings("ignore", message="numpy.dtype size changed")
warnings.filterwarnings("ignore", message="numpy.ufunc size changed")
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
%matplotlib inline
import ipywidgets as widgets
from ipywidgets import interact, interactive, fixed, interact_manual
import nbinteract as nbi
sns.set()
sns.set_context('talk')
np.set_printoptions(threshold=20, precision=2, suppress=True)
pd.options.display.max_rows = 7
pd.options.display.max_columns = 8
pd.set_option('precision', 2)
# This option stops scientific notation for pandas
# pd.set_option('display.float_format', '{:.2f}'.format)
The Walmart dataset¶
In 2014, Walmart released some of its sales data as part of a competition to predict the weekly sales of its stores. We've taken a subset of their data and loaded it below.
walmart = pd.read_csv('walmart.csv')
walmart
The data contains several interesting features, including whether a week contained a holiday (IsHoliday), the unemployment rate that week (Unemployment), and which special deals the store offered that week (MarkDown).
Our goal is to create a model that predicts the Weekly_Sales variable using the other variables in our data. Using a linear regression model we directly can use the Temperature, Fuel_Price, and Unemployment columns because they contain numerical data.
Fitting a Model Using Scikit-Learn¶
In previous sections we have seen how to take the gradient of the cost function and use gradient descent to fit a model. To do this, we had to define Python functions for our model, the cost function, the gradient of the cost function, and the gradient descent algorithm. While this was important to demonstrate how the concepts work, in this section we will instead use a machine learning library called scikit-learn which allows us to fit a model with less code.
For example, to fit a multiple linear regression model using the numerical columns in the Walmart dataset, we first create a two-dimensional NumPy array containing the variables used for prediction and a one-dimensional array containing the values we want to predict:
numerical_columns = ['Temperature', 'Fuel_Price', 'Unemployment']
X = walmart[numerical_columns].as_matrix()
X
y = walmart['Weekly_Sales'].as_matrix()
y
Then, we import the LinearRegression class from scikit-learn (docs), instantiate it, and call the fit method using X to predict y.
Note that previously we had to manually add a column of all $1$'s to the X matrix in order to conduct linear regression with an intercept. This time, scikit-learn will take care of the intercept column behind the scenes, saving us some work.
from sklearn.linear_model import LinearRegression
simple_classifier = LinearRegression()
simple_classifier.fit(X, y)
We are done! When we called .fit, scikit-learn found the linear regression parameters that minimized the least squares cost function. We can see the parameters below:
simple_classifier.coef_, simple_classifier.intercept_
To calculate the mean squared cost, we can ask the classifier to make predictions for the input data X and compare the predictions with the actual values y.
predictions = simple_classifier.predict(X)
np.mean((predictions - y) ** 2)
The mean squared error looks quite high. This is likely because our variables (temperature, price of fuel, and unemployment rate) are only weakly correlated with the weekly sales.
There are two more variables in our data that might be more useful for prediction: the IsHoliday column and MarkDown column. The boxplot below shows that holidays may have some relation with the weekly sales.
sns.pointplot(x='IsHoliday', y='Weekly_Sales', data=walmart);
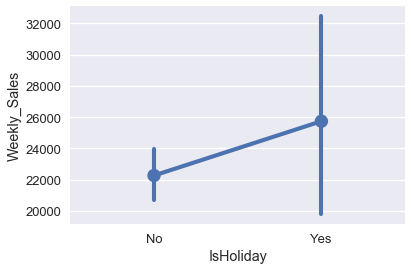
The different markdown categories seem to correlate with different weekly sale amounts well.
markdowns = ['No Markdown', 'MarkDown1', 'MarkDown2', 'MarkDown3', 'MarkDown4', 'MarkDown5']
plt.figure(figsize=(7, 5))
sns.pointplot(x='Weekly_Sales', y='MarkDown', data=walmart, order=markdowns);
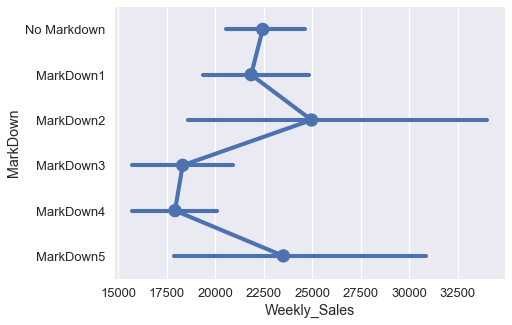
However, both IsHoliday and MarkDown columns contain categorical data, not numerical, so we cannot use them as-is for regression.
The One-Hot Encoding¶
Fortunately, we can perform a one-hot encoding transformation on these categorical variables to convert them into numerical variables. The transformation works as follows: create a new column for every unique value in a categorical variable. The column contains a $1$ if the variable originally had the corresponding value, otherwise the column contains a $0$. For example, the MarkDown column below contains the following values:
# HIDDEN
walmart[['MarkDown']]
This variable contains six different unique values: 'No Markdown', 'MarkDown1', 'MarkDown2', 'MarkDown3', 'MarkDown4', and 'MarkDown5'. We create one column for each value to get six columns in total. Then, we fill in the columns with zeros and ones according the scheme described above.
# HIDDEN
from sklearn.feature_extraction import DictVectorizer
items = walmart[['MarkDown']].to_dict(orient='records')
encoder = DictVectorizer(sparse=False)
pd.DataFrame(
data=encoder.fit_transform(items),
columns=encoder.feature_names_
)
Notice that the first value in the data is "No Markdown", and thus only the last column of the first row in the transformed table is marked with $1$. In addition, the last value in the data is "MarkDown1" which results in the first column of row 142 marked as $1$.
Each row of the resulting table will contain a single column containing $1$; the rest will contain $0$. The name "one-hot" reflects the fact that only one column is "hot" (marked with a $1$).
One-Hot Encoding in Scikit-Learn¶
To perform one-hot encoding we can use scikit-learn's DictVectorizer class. To use the class, we have to convert our dataframe into a list of dictionaries. The DictVectorizer class automatically one-hot encodes the categorical data (which needs to be strings) and leaves numerical data untouched.
from sklearn.feature_extraction import DictVectorizer
all_columns = ['Temperature', 'Fuel_Price', 'Unemployment', 'IsHoliday',
'MarkDown']
records = walmart[all_columns].to_dict(orient='records')
encoder = DictVectorizer(sparse=False)
encoded_X = encoder.fit_transform(records)
encoded_X
To get a better sense of the transformed data, we can display it with the column names:
pd.DataFrame(data=encoded_X, columns=encoder.feature_names_)
The numerical variables (fuel price, temperature, and unemployment) are left as numbers. The categorical variables (holidays and markdown) are one-hot encoded. When we use the new matrix of data to fit a linear regression model, we will generate one parameter for each column of the data. Since this data matrix contains eleven columns, the model will have twelve parameters since we fit extra parameter for the intercept term.
Fitting a Model Using the Transformed Data¶
We can now use the encoded_X variable for linear regression.
clf = LinearRegression()
clf.fit(encoded_X, y)
As promised, we have eleven parameters for the columns and one intercept parameter.
clf.coef_, clf.intercept_
We can compare a few of the predictions from both classifiers to see whether there's a large difference between the two.
walmart[['Weekly_Sales']].assign(
pred_numeric=simple_classifier.predict(X),
pred_both=clf.predict(encoded_X)
)
It appears that both models make very similar predictions. A scatter plot of both sets of predictions confirms this.
plt.scatter(simple_classifier.predict(X), clf.predict(encoded_X))
plt.title('Predictions using all data vs. numerical features only')
plt.xlabel('Predictions using numerical features')
plt.ylabel('Predictions using all features');
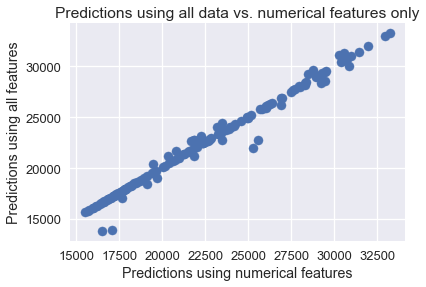
Model Diagnosis¶
Why might this be the case? We can examine the parameters that both models learn. The table below shows the weights learned by the classifier that only used numerical variables without one-hot encoding:
# HIDDEN
def clf_params(names, clf):
weights = (
np.append(clf.coef_, clf.intercept_)
)
return pd.DataFrame(weights, names + ['Intercept'])
clf_params(numerical_columns, simple_classifier)
The table below shows the weights learned by the classifier with one-hot encoding.
# HIDDEN
pd.options.display.max_rows = 13
display(clf_params(encoder.feature_names_, clf))
pd.options.display.max_rows = 7
We can see that even when we fit a linear regression model using one-hot encoded columns the weights for fuel price, temperature, and unemployment are very similar to the previous values. All the weights are small in comparison to the intercept term, suggesting that most of the variables are still only slightly correlated with the actual sale amounts. In fact, the model weights for the IsHoliday variable are so low that it makes nearly no difference in prediction whether the date was a holiday or not. Although some of the MarkDown weights are rather large, many markdown events only appear a few times in the dataset.
walmart['MarkDown'].value_counts()
This suggests that we probably need to collect more data in order for the model to better utilize the effects of markdown events on the sale amounts. (In reality, the dataset shown here is a small subset of a much larger dataset released by Walmart. It will be a useful exercise to train a model using the entire dataset instead of a small subset.)
Summary¶
We have learned to use one-hot encoding, a useful technique for conducting linear regression on categorical data. Although in this particular example the transformation didn't affect our model very much, in practice the technique is used widely when working with categorical data. One-hot encoding also illustrates the general principle of feature engineering—it takes an original data matrix and transforms it into a potentially more useful one.